配置
应用与微服务中提供4种级别的选项配置,配置级别(即配置的顺序)从高到低分别是全局配置、业务系统配置、应用配置和实例配置。部分配置项会同时出现在多种级别的配置页,配置生效情况说明如下:
-
如果在低级别的配置中选择使用上级配置时,当前级别的被监控对象继承并保持与上一级完全一样的设置值。
-
如果低级别的配置中勾选了单独配置功能,且打开开关设置了与上级配置不一样的设置值,则当前低级别的设置值会生效,即配置生效的优先级为:
全局配置<业务系统配置<应用配置<实例配置。 -
如果低级别的配置中勾选了单独配置功能,但是没有打开开关,则代表当前监控对象不启用该功能。
全局配置
全局配置的配置项允许用户设置对整个系统统一生效,包括日志溯源开关、开启追踪、错误及异常采集设置和探针熔断等选项。
常规选项
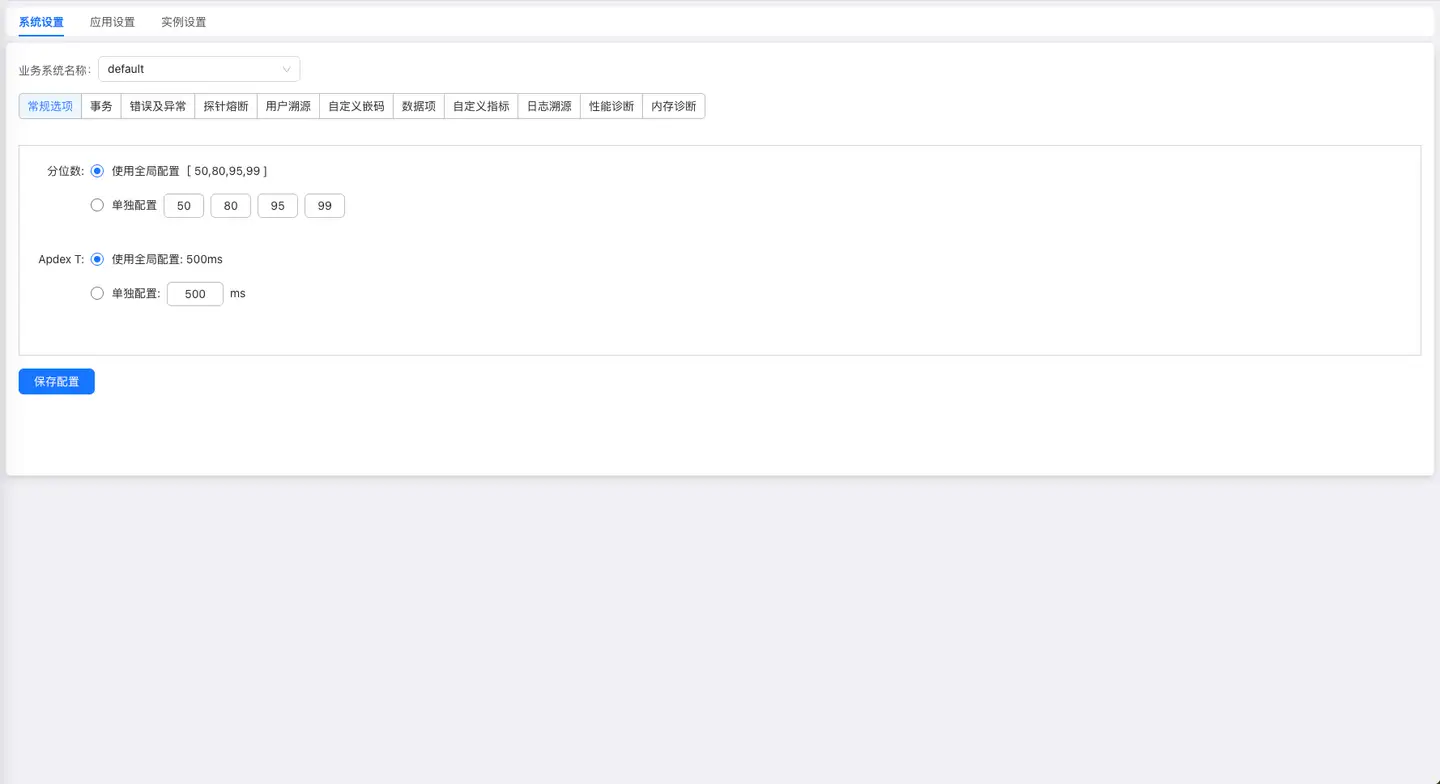
Apdex T
Apdex 定义了应用响应时间的最优门槛 T(即Apdex T),另外根据应用响应时间结合T 定义了三种不同的性能表现:
-
Satisfied(满意):应用响应时间低于或等于 T(T由性能评估人员根据预期性能要求确定),则认为用户对应用的性能表现满意。比如 T为 1.5s,则一个耗时 1s 的响应结果则可以认为是满意的。
-
Tolerating(可容忍):应用响应时间大于 T,但同时小于或等于4T。假设应用设定的 T 值为 1s,则 4 * 1 = 4 秒,即为应用响应时间的容忍上限。
-
Frustrated(不能忍受):应用响应时间大于4T。另外,当一个请求的响应状态码为400及以上(401除外)或发生最外层异常时,无论响应时间长短,均归类为不能忍受。
应用与微服务取应用的平均响应时间作为计算指标,默认定义Apdex T 为 500毫秒。全局配置中的Apdex T配置适用于所有业务系统中的应用。
Apdex标准从用户的角度出发,对真实的响应时间进行采样,采集一定时间之后,将应用响应时间的表现,转化为用户对于应用性能的可量化的满意度评价,我们称之为Apdex指数,范围为0~1。0代表对所有请求响应时间的表现都不满意,1代表对所有请求响应时间的表现都满意。
计算公式为: Apdex指数 =(满意数+可容忍数/2)/成功次数
日志溯源
Java Agent 3.6.3.3及以下版本
一个请求往往会跨越很多个应用,请求的日志都分散在各个应用下,查找单次请求的所有日志较为困难。日志溯源功能可以很好的解决这个问题。开启日志溯源功能后,探针可以自动在用户的日志内容中输出NBS.APPID和NBS.REQUEST_GUID属性,通过NBS.REQUEST_GUID属性可以关联不同应用和实例上单次请求的日志。当用户通过分布式链路追踪到慢请求时,可以根据该次慢追踪的追踪ID在应用日志中查询该慢请求的所有日志信息。
说明:
- NBS.REQUEST_GUID即追踪ID。
- 日志溯源默认是关闭状态。
- 只有对Java应用支持该功能。
- 日志溯源功能支持主流的Log4j和Logback日志框架。
- 要使用日志溯源功能,链路的所有应用都需要部署基调听云APM探针。
配置日志溯源,请按照以下步骤进行操作:
-
如果应用初次使用该功能,需要在探针配置文件tingyun.properties中开启以下设置。
# 日志追溯相关Plugin,开启后可以在应用的日志中,打印应用与微服务相关数据,如应用ID、追踪ID等。
class_transformer.tingyun-log4j-plugin-2.0.0.enabled=true
class_transformer.tingyun-log4j-plugin-2.3.enabled=true
class_transformer.tingyun-log4j-plugin-1.2.enabled=true
class_transformer.tingyun-logback-plugin-1.2.enabled=true -
登录应用与微服务控制台,在左侧导航栏中选择全局配置,在常规选项页签中开启日志溯源功能。
-
配置被监控应用的日志配置文件。
-
Log4j配置
log4j.appender.order-file-appender.layout.ConversionPattern=[%d] [%-5p] [%t]
[%c] [%R][%A]%m%n -
Log4j2配置
<Console name="Console" target="SYSTEM_OUT"\>
<PatternLayout pattern="%d{HH:mm:ss.SSS} [log4j2] %-5level %logger{36} -
%msg%n[%A][%R]"/\>
</Console\> -
Logback配置
<encoder\>
<pattern\>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} -
%msg%n[%A][%R]\</pattern\>
</encoder\>
-
-
查看输出的应用日志。
例如,Log4j日志输出格式如下:
2020-10-29T16:30:27,730-07:00][DEBUG][com.tingyun.Log-0][com.tingyun.Test][NBS.REQUEST_GUID:167d328d-b82a-4b8c-8049-7a3a13af158f][NBS.APPID:0017]
Test Log Message其中,[%R]负责输出请求的NBS.REQUEST_GUID,配置后日志会增加NBS.REQUEST_GUID信息。在整个请求链路中,入口事务生成的NBS.REQUEST_GUID将作为整个请求链路的唯一标识,此值将在链路中不断传递直到链路的最后请求(如果遇到无法实现跨应用追踪的组件的情况除外),以实现全链路追踪。调用链所涉及的各个应用的日志都显示同一个NBS.REQUEST_GUID。[%A]负责输出应用的NBS.APPID,是应用与微服务系统为每一个监控的应用生成的唯一id,配置后日志会增加NBS.APPID信息。如果日志溯源功能是关闭的,即使用户配置了[%R],NBS.REQUEST_GUID也不会被嵌入。
Java Agent 3.6.4及以上版本
一个事务往往会跨越很多个应用,事务的日志都分散在各个应用下,查找单次请求的所有日志较为困难。应用与微服务的日志溯源功能可以很好的解决这个问题。开启日志溯源功能后,APM探针可以自动在用户的日志内容中输出tingyun.app_id、tingyun.trace_id和tingyun.span_id属性,通过tingyun.trace_id属性可以关联不同应用和实例上单次请求的日志。当用户通过应用与微服务追踪到慢事务时,可以根据该次慢追踪的追踪ID在应用日志中查询该慢事务的所有日志信息。
说明:
- tingyun.trace_id即基调听云应用与微服务控制台页面中的追踪ID。
- 日志溯源默认是关闭状态。
- 只有对Java应用支持该功能。
- 日志溯源功能支持主流的Log4j和Logback日志框架。
- 要使用日志溯源功能,链路的所有应用都需要部署基调听云APM探针。
配置日志溯源,请按照以下步骤进行操作:
-
登录应用与微服务控制台,在左侧导航栏中选择全局配置,在常规选项页签中开启日志溯源功能。
-
默认情况下,探针采用自动注入方式在日志中增加tingyun.app_id、tingyun.trace_id和tingyun.span_id属性。该方式的优点是探针自动将数据写入应用日志,无需修改应用配置。缺点是您不能在日志配置文件中自定义上述属性输出的位置。
日志输出示例:
2022-03-24 16:43:52.302 [http-nio-8079-exec-1] INFO [tingyun.app_id:2503,tingyun.trace_id:77469a69f8b9fdce,tingyun.span_id:77469a69f8b9fdce] com.tyt.controller.LogbackController -Thread[http-nio-8079-exec-1,5,main] -
如果您的环境中对日志格式做了一些定义,日志溯源可能影响日志解析,此时如果您仍想使用日志溯源功能,可根据业务自定义输出位置。您可采用手动注入方式(不推荐),该方式需要配置被监控应用的日志配置文件。例如,您希望将上述属性输出在日志的最前面,可做如下配置:
log4j.appender.order-file-appender.layout.ConversionPattern= [TINGYUN] [%d] [%-5p] [%t] [%c]%m%n日志输出示例:
[tingyun.app_id:2503,tingyun.trace_id:77469a69f8b9fdce,tingyun.span_id:77469a69f8b9fdce] 2022-03-24 16:43:52.302 [http-nio-8079-exec-1] INFO com.tyt.controller.LogbackController -Thread[http-nio-8079-exec-1,5,main]其中,[TINGYUN]负责输出请求的tingyun.app_id、tingyun.trace_id和tingyun.span_id。在整个请求链路中,入口事务生成的tingyun.trace_id将作为整个请求链路的唯一标识,此值将在链路中不断传递直到链路的最后请求(如果遇到无法实现跨应用追踪的组件的情况除外),以实现全链路追踪。调用链所涉及的各个应用的日志都显示同一个tingyun.trace_id。tingyun.app_id是应用与微服务为每一个监控的应用生成的唯一id。tingyun.span_id是应用与微服务为请求链路中每一段请求生成的唯一id。如果日志溯源功能是关闭的,即使用户配置了[TINGYUN],上述3个属性也不会被嵌入。
采样
采样是针对链路追踪数据是否保留的一种策略。开启采样不会对指标数据造成影响。基调听云平台通过“调用链采样”和“请求采样”两种模式实现采样,两种模式只能开启其中一种。
调用链采样
默认情况下,应用与微服务探针提供全量的业务和性能数据采集。但是在应用访问量比较大时,为了让探针减少对CPU、内存等资源的消耗,可以对采集的调用链数据按照一定的比例进行保留,这样能够帮助您以较低的性能开销记录最有价值的链路数据。调用链采样适用于以下场景:
- 压测或大促期间流量过大,为了避免调用链数据全量上传影响客户端性能,可以考虑按需调整采样率的比例。
- 日常情况下,全量调用链数据上传导致网络带宽成本高,可以考虑按需调整采样率的比例。
调用链采样就是根据追踪ID记录一定比例的调用链数据。例如,固定比例为10‰,则每1000条调用链数据记录10条。采样不会导致调用链数据本身不完整,要么保留整条链路数据,要么丢弃整条链路数据。开启调用链采样后,Agent Collector在保障调用链完整的情况下,依据采样率保留事务追踪,性能汇总数据依然保持全量采集。默认调用链采样开关为关闭状态,开启后,默认采样率为5‰,请�根据实际需要调整采样率。
说明: 仅V3.6.1.2以上版本的Agent Collector支持调用链采样。
请求采样
开启请求采样后,基调听云平台将忽略调用链完整性诉求,依据作用在实例级上的采样配置,针对每次请求,保留其追踪数据。该模式下,链路完整性无法保证,请谨慎开启。
您可以根据固定比例或者固定个数两种模式来采集链路追踪数据。
- 默认情况下,每实例每分钟采集5‰的链路追踪数据,可根据实际需要进行配置。
- 默认情况下,每实例每分钟固定采集10000个链路追踪数据,可根据实际需要进行配置。
获取源代码
说明: 仅私有化部署模式下支持使用该功能。
为了更快速地帮助用户找到代码问题,应用与微服务可通过获取用户应用的源代码进行问题分析。此处的源代码是指从JVM ClassLoader 中获取Java Classs文件,经反编译而转存的代码。基调听云不会主动获取任何Classes文件,只有当用户手动触发获取源文件时,才从JVM中动态获取。转存的Class文件,只供用户在线反编译使用,不会做其他用处。基调听云不会向任何第三方分发,暂存在磁盘上7天后会自动清理。
要获取源代码,请按以下步骤进行操作:
-
实施人员配置Nacos组件的apm-api和apm-config,将applicaticonService.showSourceCode的值改为 1。默认值为0,报表上�不显示获取源代码功能项。
-
在报表上开启获取源代码功能。
-
重启应用。
用户可在分布式追踪页面详情页的Call Tree中,查看某个类的源代码。
追踪选项
-
慢请求阈值:当请求的响应时间大于阈值时,会被应用与微服务标记为慢请求。
-
慢方法堆栈:对于请求涉及的方法、SQL语句、NoSQL操作、自定义方法,当执行时间大于阈值时才记录方法的堆栈、慢SQL详情和慢NoSQL操作详情。默认开启。
-
混淆SQL:指对跟踪到的SQL语句中的数字和字符串值进行混淆操作,以问号“?”替换。默认开启。仅对慢 SQL 追踪和请求追踪生效。
-
采集请求参数:采集HTTP的请求头和请求参数。默认开启。
-
忽略的参数列表:如果不想采集个别敏感的参数,可以进行设置,多个参数以英文逗号进行分隔。
-
GenAI监控:开启该监控后探针将采集GenAI的调用情况,目前仅Python3.4.8.0+支持,默认开启。
错误及异常
-
采集错误和异常:开启时,应用探针将采集各业务系统中所有应用的错误和异常信息。默认为开启状态。
-
捕捉异常堆栈:启用后,事务追踪中的异常信息将包含堆栈信息。默认为关闭状态。
-
选择语言类型:目前支持Java、.NET和.NET Core三种语言。不同语言显示的配置项不同。
-
采集日志异常:勾选Log4j或Logback复选框后,可采集和统计日志组件输出的error及以上级别日志中的异常信息,例如应用输出了日志log.error("message","IOException"),那么IOException将会被采集。.NET和.NET Core还支持System日志组件。当勾选日志组件的复选框后,就可以勾选日志级别高于‘error’的’message‘和设置事务状态为错误复选框了。
- 日志级别高于‘error’的’message‘:默认情况下,对于error及以上级别的日志,如果日志中只有message,而没有异常信息,是不会被统计为异常的。勾选该复选框后,上述日志也会被统计为异常。
- 设置事务状态为错误:勾选后,error及以上级别的日志所对应的事务会被视为错误,否则只被视为异常。Logback只有error级别的日志。
-
根据Logged Message忽略:符合日志信息匹配规则的日志异常不会被视为异常或错误。单击添加按钮,选择信息匹配方式,输入异常信息,该处不支持正则表达式。规则可被编辑和删除。
-
根据异常类忽略:您可将不想计入错误和异常的异常类加入列表,后续统计错误时这些类将被忽略。单击添加按钮,输入包含包名的完整异常类名。可勾选Exception Message 过滤复选框,通过exception.getMessage() 打印出的异常信息忽略异常,如果匹配成功,则该Exception不会被认为是Exception。选择信息匹配方式,输入异常信息,该处不支持正则表达式。规则可被编辑和删除。
- 自定义HTTP状态码:默认情况下,基调听云会将 Status Code 400 ~ 505 的事务状态设置为错误。但是业务上的错误可能并不符合这个规则,如:900 在金融场景下可能代表“余额不足”,需要被作为事务错误,而401被认为是正常的事务请求。通过自定义HTTP状态码,可分别设置错误状态码和正常状态码来标识事务是否正常,以符合上述2种场景的需要。“错误状态码”类型的自定义HTTP Status code的名称在错误分析中会作为错误类型显示,格式为: HTTP Error Code: $
{名称}。状态码规则可被编辑、删除和批量删除。
- 自定义HTTP状态码:默认情况下,基调听云会将 Status Code 400 ~ 505 的事务状态设置为错误。但是业务上的错误可能并不符合这个规则,如:900 在金融场景下可能代表“余额不足”,需要被作为事务错误,而401被认为是正常的事务请求。通过自定义HTTP状态码,可分别设置错误状态码和正常状态码来标识事务是否正常,以符合上述2种场景的需要。“错误状态码”类型的自定义HTTP Status code的名称在错误分析中会作为错误类型显示,格式为: HTTP Error Code: $
说明:
- 该选项必须在采集错误和异常选项开启的情况下才生效。
- 当某个状态码同时被设置成了错误状态码和正常状态码时,基调听云将会根据配置项的优先级判定最终是错误状态码还是正常状态码,排列越靠上的优先级越高。
- 自定义业务错误:业务错误指业务上的一些非正常结果,通过对数据项的值进行规则定义,来识别业务错误。当满足业务错误的规则时,事务的状态会被设置为错误,错误的名称为自定义业务错误的描述。业务错误在错误模块中可以独立分析其趋势、堆栈、调用者、调用栈及请求上下文。单击添加按钮,输入业务错误描述,选择数据项(支持创建新的数据项),对值设置匹配规则后,单击确认。匹配规则最多可添加3条。自定义业务错误可被编辑、删除和批量删除。
- 自定义Redirect Pages:当用户在操作应用的过程中,经常遇到操作失败后跳转到一个错误提示页面的情况。您可以对应用中发生错误后重定向到的错误页面进行定义,当匹配成功后,操作对应的这个事务的状态会被设置为错误。单击添加按钮,输入名称,设置匹配条件和重定向页面的URL,单击确认。自定义Redirect Pages可被编辑、删除和批量删除。
探针熔断
Java Agent在运行过程中会消耗应用进程的资源,包括CPU和内存,当应用进程资源紧张时,为了应用进程稳定运行,Java Agent将触发熔断机制,关闭部分数据采集以减少对进程资源的消耗。
相关名词解释如下:
-
Heap内存:JVM堆内存。
-
Garbage Collection:JVM垃圾回收机制。
-
Garbage Collection CPU时间占比:Garbage Collection消耗的CPU时间/CPU总时间。
触发探针熔断有两种情况:
1、当Heap内存使用率超过配置值时(默认值:70%)或者Garbage Collection CPU时间占比超过配置值时(默认值:10%),将对数据采集进行采样(默认值:50%)。
2、当Heap内存使用率超过配置值时(默认值:80%)或者Garbage Collection CPU时间占比超过配置值时(默认值:20%),将禁用数据采集,但仍保留探针心跳。
当应用进程的资源恢复后,恢复数据采集。
系统配置
业务系统配置作用于每个独立的业务系统。如果您希望业务系统的配置情况与全局配置完全一致,可以选择从全局配置中继承设置值。您也可以单独配置每个业务系统自己的独立配置。
除分位数、用户溯源自定义嵌码、数据项和自定义指标外,其他的业务系统配置项和全局配置的的配置项完全相同。
常规选项��
分位数:对于指定的业务系统,您可以单独设置要显示的分位值曲线,即勾选单独配置后进行设置。业务系统相关的分位值统计图表默认展示50、80、95和99分位值曲线。
用户溯源
当需要追踪某一个请求是哪个用户进行的,请先设置用户信息获取方式。当发生慢请求追踪时,应用与微服务会根据您设置的数据源按照优先级抓取用户标识,直到获取到为止。当您在分布式链路追踪页面查看列表时,只需查看用户标识一列,就可以知道慢请求是由哪个用户触发的。
注意:Java Agent 在配置用户溯源时,当应用中存在跨应用或开启基调听云Web嵌码时,会向Header或Cookie中写入数据,当应用本身写入Header或Cookie的数据加上Java Agent写入的数据长度大于Header或Cookie限制的长度时,导致应用写Header或Cookie失败,进而导致应用报错。Java Agent 3.6.2.1对写入Header或Cookie的数据做了长度限制,默认为50个字符。这种修改方式不能完全避免问题,但能大大降低问题发生的可能性。
配置获取方式
配置用户溯源,单击添加数据源,在下拉列表中选择获取方式,包括以下几种方式:
-
Java method parameter(s):从方法参数获取,该方式为默认方式。通过该方式获取参数会自动生成一条自定义嵌码,并自动执行,显示在自定义嵌码页签中。�在Class搜索框中输入类名的关键字,找到类名后,在Method部分选择要获取用户标识参数所在的方法,然后选择要获取的参数。
-
p1:xxxx或p2:xxxx代表当前方法的参数,按方法入参的顺序排序。
-
this:当前Class的this对象。
-
Getter Chain:方法调用链,可以获取对象中一个具体的值,例如getPerson().getName()。
-
Web request query parameter:从请求的URL参数获取。在文本框中输入代表用户信息的参数名称。
-
HTTP request header:从HTTP请求头中的参数获取。在文本框中输入代表用户信息的参数名称。
-
HTTP post parameter:从HTTP请求体中的参数获取。在文本框中输入代表用户信息的参数名称。
-
HTTP response header:从HTTP响应头中的参数获取。在文本框中输入代表用户信息的参数名称。
-
Servlet session attribure:从Session中保存用户标识的参数获取。在Key文本框中输入代表用户信息的属性名称。如果需要获取对象中一个具体的值,请填写Getter Chain方法调用链,例如getPerson().getName()。
-
Web request path:从请求URL的URI部分获取。
-
HTTP cookie:从Cookie中保存用户标识的参数获取。在文本框中输入代表用户信息的参数名称。
数据处理
某些情况下,获取到的参数信息并不是准确的用户信息,例如参数中的某个字段才是真正的用户信息,对于这种情况,您可以勾选数据处理,对参数进行二次精确,包括between、before和after三种方式。例如Web请求为https://help.tingyun.com/document_detail/106690.html?spm=a2c4g-11174359.6.643.54e960f80sE7s8,其中spm这个参数中只有“-”前面的部分为用户信息,那么我们将Substring方式设置为before,内容设置为“-”,基调听云APM获取到的用户信息为a2c4g。您还可以在下方的预览文本框中输入测试内容,单击查看结果进行确认。
管理数据源
单击保存配置后,新添加的数据源将会显示在列表的最上方,即优先级最高。您可以单击顺序列中的箭头来调整数据源的优先级,排列越靠上,优先级越高。表示移到顶部,表示移到底部。表示上移一行,表示下移一行。基调听云APM会按照优先级依次匹配数据源获取用户标识。当您不想使用某个数据源时,可在状态栏中将其关闭。
在搜索框中可根据Key的关键字搜索数据源。
自定义嵌码
用户可以对各种非标准化应用组件的某个方法或者基调听云暂不支持的组件的某个方法进行监控。当方法被调用时,探针将对该方法进行性能数据(如调用次数、平均响应时间等)搜索,获取到的内容将在事务分解表格、事务追踪的调用栈中进行展示。
自定义嵌码状态栏:自定义嵌码状态开关开启后,您所配置的自定义嵌码可以被执行。关闭后,仍然可以配置自定义嵌码,但是不能执行嵌码。
未执行的嵌码列表:显示配置完成但还未执行嵌码的��自定义嵌码配置。单击右上方的添加自定义嵌码按钮,您可以通过代码包添加和手工录入两种方式配置。
通过代码包添加
当您不能准确的输入具体的类名和方法名时,可以在应用的代码中按层级来定位方法,基础包不会显示在此处。在下拉菜单中选择应用,可以通过类名、方法名或者参数名来搜索,匹配到的内容将会显示为蓝色,搜索到的方法会自动被展开展示。您也可直接单击可展开包和类,以便定位到方法。括号中是方法的参数类型,最后显示的是返回值类型。勾选忽略方法参数后,方法中的参数会显示为省略号,如下图所示,重载的方法会合并显示为一个。
在左侧确定一个或多个方法后,右侧面板中会显示嵌码选项和当调用方法时忽略事务两个选项按钮**。
-
嵌码选项:
-
包含子类:勾选后,当前方法所在的类的所有子类都会被监控到。
-
入口方法:有些方法由于没有入口方法,就算自定义嵌码了也不会作为一个事务显示,因此这类方法如果要作为一个事务来监控,必须要勾选该项。
-
命名事务/业务接口:勾选后,该方法的名称将作为事务名称或服务接口名称。事务或服务接口的命名方式为:Custom/类名/方法名。如果不勾选,事务名称是默认的一些方法名。
-
采集方法参数:勾选后,可以采集当前方法的参数。属性名称是给参数一个命名,默认会生成一个数据项,并展示在数据项页签列表中。只有配置了属性名称的参数才会被采集。当参数类型为对象时,如果您还想采集具体的一个值,请配置Getter Chain。如果需要在命名事务后的名称中继续加入参数的值,请勾选参数命名复选框,该复选框只有在命名事务/业务接口和采集方法参数功能同时开启的情况下才可勾选。命名方式为:Custom/类名/方法名?key=参数值。
-
-
当调用方法时忽略事务:当该方法被调用时,该方法所涉及的事务不会被监控到,即事务列表或者事务追踪列表中不会再出现上述事务。
手工录入
如果您对应用代码非常熟悉,可以使用该方式。包含5种匹配规则(即Match Type),说明如下:
-
Class method by signature:请准确的输入类名(包括包名)和方法名。
-
忽略方法参数:不管该方法有几个参数,所有参数都会被采集。
-
指定方法参数:由于在Java代码中会出现方法重载的情况,因此需要指定参数类型来唯一确定一个方法。在重载的情况下,只采集与配置的参数个数一样的方法。例如拥有相同方法名称的方法有3个,分别有1个参数、2个参数和3个参数,我们只配置了一个参数类型,则基调听云APM只采集1个参数的方法。
-
嵌码选项:请参见通过代码包添加下的嵌码选项说明。
-
当调用方法时忽略事务:当该方法被调用时,该方法所涉及的事务不会被监控到,即事务列表或者事务追踪列表中不会再出现上述事务。
-
-
Class method by return type:请准确的输入类名(包括包名)和返�回值类型。
-
包含子类:勾选后,只要是包含该返回值类型的方法所在的类的所有子类都会被监控到。
-
入口方法:有些方法由于没有入口方法,就算自定义嵌码了也不会作为一个事务显示,因此这类方法如果要作为一个事务来监控,必须要勾选该项。
-
命名事务/业务接口:勾选后,该方法的名称将作为事务名称或服务接口名称。事务或服务接口的命名方式为:Custom/类名/方法名。如果不勾选,事务名称是默认的一些方法名。
-
采集方法返回值:勾选后,可以采集该类中包含该返回值类型的方法的返回值。属性名称是给返回值一个命名,默认会生成一个数据项,并展示在数据项页签列表中。当返回值类型为对象时,如果您还想采集具体的一个值,请配置Getter Chain。
-
当调用方法时忽略事务:当该类中包含该返回值类型的方法被调用时,所涉及的事务不会被监控到,即事务列表或者事务追踪列表中不会再出现上述事务。
-
-
Interface method by signature:请准确的输入接口名和方法名。
-
忽略方法参数:不管该方法有几个参数,所有参数都会被采集。
-
指定方法参数:在重载的情况下,只采集与配置的参数个数一样的方法。例如拥有相同方法名称的方法有3个,分别有1个参数、2个参数和3个参数,我们只配置了一个参数类型,则基调听云APM只采集1个参数的方法。
-
嵌码选项:请参见通过代码包添加下的嵌码选项说明。
-
当调用方法时忽略事务:当该方法被调用时,该方法所涉及的事务不会被监控到,即事务列表或者事务追踪列表中不会再出现上述事务。
-
-
Interface method by signature:请准确的输入接口名和返回值类型。
-
入口方法:有些方法由于没有入口方法,就算自定义嵌码了也不会作为一个事务显示,因此这类方法如果要作为一个事务来监控,必须要勾选该项。
-
命名事务/业务接口:勾选后,该方法的名称将作为事务名称或服务接口名称。事务或服务接口的命名方式为:Custom/类名/方法名。如果不勾选,事务名称是默认的一些方法名。
-
采集方法返回值:勾选后,可以采集包含该返回值类型的方法的返回值。属性名称是给返回值一个命名,默认会生成一个数据项,并展示在数据项页签列表中。当返回值类型为对象时,如果您还想采集具体的一个值,请配置Getter Chain。
-
当调用方法时忽略事务:当包含该返回值类型的方法被调用时,所涉及的事务不会被监控到,即事务列表或者事务追踪列表中不会再出现上述事务。
-
-
Method annotation for class:请准确输入注解名。
-
入口方法:有些方法由于没有入口方法,就算自定义嵌码了也不会作为一个事务显示,因此这类方法如果要作为一个事务来监控,必须要勾选该项。
-
命名事务/业务接口:勾选后,该方法的名称将作为事务名称或服务接口名称。事务或服务接口的命名方式为:Custom/类名/方法名。如果不勾选,事务名称是默认的一些方法名。
-
当调用方法时忽略事务:当包含该注解名的方法被调用时,所涉及的事务不会被监控到,即事务列表或者事务追踪列表中不会再出现上述事务。
-
管理自定义嵌码规则
自定义嵌码创建完成后,会显示在未执行的嵌码列表中,默认为开启状态。如果您不想在单击执行嵌码按钮后对某一条配置进行嵌码,可以在Enable列关闭该条配置。在搜索框中输入类名、接口名、方法注解名、返回值类型或者方法名,都可以对列表进行搜索。
已执行的嵌码列表:单击最下方的执行嵌码按钮后,开启状态的自定义嵌码配置开始执行,显示在该列表中。包含四种状态:
-
嵌码成功:业务系统中所有应用的所有实例都执行嵌码成功。
-
部分成功:业务系统中部分应用的部分实例执行嵌码成功,部分失败。
-
嵌码失败:业务系统中所有应用的所有实例都执行嵌码失败。
-
等待执行:按照计划等待执行中。探针5分钟内有心跳才可执行自定义嵌码。
执行完成的自定义嵌码配置可以在Enable列关闭,目的是让探针停止采集该条配置的数据。在搜索框中输入类名、接口名、方法注解名、返回值类型或者方法名,都可以对列表进行搜索。
数据项
用户可以将业务相关的参数定义为一个数据项。数据项可以被自定义指标所使用。单击右上角的添加按钮,进行数据项的配置。
-
名称:输入数据项的名称。
-
数据类型:选择数据项的数据类型,包括String、Integer和Double三种类型。
-
当出现多值时,保留:对于一个请求,同一个方��法可能会被调用多次,例如方法的递归调用,每次调用时入口参数的值很可能会不同,这时,您可以设置保留第一个(取第一次调用时参数的值)、最后一个(取最后一次调用时参数的值)或者取出现次数。
-
添加数据项来源:来源包括以下8种方式。
-
Java method parameter(s):从方法参数获取,该方式为默认方式。通过该方式获取参数会自动生成一条自定义嵌码,并自动执行,显示在自定义嵌码页签中。在Class下拉菜单中选择类名后(支持搜索),在Methods部分选择要作为数据源来源的参数所在的方法,然后选择要获取的数据源。
-
Class name:类名,包含包名。
-
Simple class name:简单类名,不包含包名。
-
Method name:方法名。
-
this:当前Class的this对象。当需要获取对象中一个具体的值时可以填写Getter Chain,例如getPerson().getName()。
-
p1:xxxx或p2:xxxx代表当前方法的参数,按方法入参的顺序排序。
-
-
Web request query parameter:从请求的URL参数获取。在文本框中输入代表该数据项的参数名称。
-
HTTP request header:从HTTP请求头中的参数获取。在文本框中输入代表该数据项的参数名称。
-
HTTP post parameter:从HTTP请求体中的参数获取。在文本框中输入代表该数据项的参数名称。
-
HTTP response header:从HTTP响应头中的参数获取。在文本框中输入代表该数据项的参数名称。
-
Servlet session attribure:从Session中获取参数。在文本框中输入代表该数据项的属性名称。如果需要获取对象中一个具体的值,请填写Getter Chain方法调用链,例如getPerson().getName()。
-
Web request URL:��从请求的URL获取。
-
Web request path:从请求URL的URI部分获取。
-
数据处理
某些情况下,获取到的参数信息并不是准确的数据源信息,例如参数中的某个字段才是真正的用户信息,对于这种情况,您可以勾选数据处理,对参数进行二次精确,包括between、before和after三种方式。例如Web请求为https://help.tingyun.com/document_detail/106690.html?spm=a2c4g-11174359.6.643.54e960f80sE7s8,其中spm这个参数中只有“-”前面的部分为用户信息,那么我们将Substring方式设置为before,内容设置为“-”,基调听云APM获取到的用户信息为a2c4g。您还可以在下方的预览文本框中输入测试内容,单击查看结果进行确认。
新创建的获取来源会显示在顶部第一条,即优先级最高。从上往下优先级依次降低。基调听云APM会按照优先级依次匹配数据源获取数据项的值。当您不想使用某个获取来源时,可在启用栏中将其关闭。
自定义指标
当用户想从业务角度查看符合某个条件(例如订单金额大于100元)的事务发生次数时,可配置自定义指标来实现。
| 配置项 | 说明 |
|---|---|
| 指标名称 | 输入自定义指标的名称。 |
| 指标(SELECT) | 配置要采集的目标数据项,例如价格和数量两个数据项。该项相当于SQL语句中SELECT的作用,为必填项。 点击新建按钮进行添加,选择数据项和聚合规则,聚合规则即计算方式,会根据数据项类型的不同而改变,例如String类型只包含count,表示计数。勾选一个指标后,点击修改按钮进行修改。勾选一个或多个指标后,点击删除可直接将其删除。 |
| 过滤器(WHERE) | 配置采集目标数据项数据的条件,当满足过滤器内所有条件时探针才进行采集。该项相当于SQL语句中WHERE的作用,为可选项。 点击新建按钮进行添加,选择数据项、比较条件和数值。勾选一个指标后,点击修改按钮进行修改。勾选一个或多个指标后,点击删除可直接将其删除。 |
| 维度(GROUP BY) | 配置要采集的目标数据项的统计维度。该项相当于SQL语句中GROUP BY的分组作用,为可选项。 点击新建按钮进行添加,选择数据项即可。勾选一个或多个指标后,点击删除可直接将其删除。 |
举例说明,如果您想知道订单金额大于100的订单有多少笔,即是要统计提交订单这个业务操作所涉及的事务中金额参数大于100的发生了多少次。如假设订单金额已经被设置成了数据项“金额”,则我们可以定义自定义指标为“订单金额大于100”,指标添加“金额”,聚合规则为count。过滤器添加“金额”,比较条件为大于,值为100。维度不设置。
自定义指标的监控统结果请到应用下的自定义指标页签或者事务下的自定义指标页签查看。
单击具体的指标条目可查看统计详情。
用户可以按维度查询该指标的维度展示详情。
性能诊断
默认情况下,探针监控到的方法有限,而对于一个请求的完整调用链来说,可能会存在某个方法耗时特别长,又无法进一步细粒度的分析。全栈快照通过对请求线程做多次快照剖析,得到更为详细的调用链信息,来更准确地分析性能瓶颈。探针在收到快照采集指令后,会对某一个请求线程开启快照采集诊断会话,采集当前线程的线程名、线程ID等信息。
采集全栈快照对性能有一定的消耗,因此用户可以按需控制是否开启快照采集。开启后,还可以控制单片快照采集的时间间隔。
全栈快照的采集模式有如下三种:
-
触发采集:有条件的触发全栈快照诊断会话。
触发条件为:1分钟内慢请求占比超过指定阈值(默认值10%,数据边界:[1,100]%)且慢请求次数超过20时,启动诊断会话。诊断会话的持续时间默认为5分钟(数据边界:[1, 10]),该诊断周期内,会为每个请求,每分钟尝试采集10个(数据边界:[1, 100])快照样本,总的快照样本限制为100个(数据边界:[1, 1000])。
为了避免因为持续的性能问题而导致过多的采集快照数据,可以配置诊断会话之间的等待时间,默认诊断会话间隔10分钟(数据边界:[5, 30])。
-
固定周期采集:按照固定周期采集全栈快照。勾选复选框后才能生效。
触发条件为:每1分钟(数据边界:[1,100])采集10个全栈快照。当处于诊断会话(触发采集)时,固定周期的采集暂停。
-
强制采集:根据条件强制采集全栈快照。勾选复选框后才能生效。该模式默认关闭。
触发条件为:当请求执行时间超过3倍慢请求阈值时(数据边界:[慢请求阈值,∞]),��开启针对该请求的全栈快照,每分钟最多采集100个快照。
单击底部的保存配置按钮,配置开始生效。用户可在请求追踪详情的全栈快照页签中查看结果。
应用配置
应用设置是以应用为单位进行配置项的设置,仅对指定的应用生效。部分配置项可以继承业务系统级别的配置,在此我们将不再讲解,具体描述请见业务系统设置。需要说明的是,应用不能继承业务系统配置的自定义指标。
常规选项
-
应用别名
设置应用别名只是为了用户在界面中更方面的查看应用,便于识别。
-
自动命名事务
默认情况下,应用探针通过在Web请求的URI前加上URI前缀来命名事务,即事务名称结构为:URI/Web请求的URI部分。当启用自动命名事务功能后,应用探针根据应用框架或组件来命名事务,以增强事务的可识别性,事务名称结构为:应用框架或组件名称/Web请求的URI部分。
下面我们用一个例子来说明自动命名事务功能。假如用户从浏览器端发起一个HTTP请求,完整的URL为
http://www.tingyun.com/sql/oracleException1.do?city=beijing,如果处理该事务的组件为Servlet,当未开启自动命名事务功能时,事务的名称为URI/sql/oracleException1.do,如果开启,则事务的名称为Servlet/sql/oracleException1.do。 -
日志溯源
请参见全局配置下的日志溯源介绍。
-
启用Thrift监控
开启该功能后,通过Thrift框架进行的RPC调用会被监控到。监控非官方generator生成的Thrift程序可能会造成应用崩溃,如果有定制或者二次开发,务必在测试环境充分测试后,谨慎开启此功能。
-
MQ消费端监控
监控MQ消费端可能造成应用处理消息能力下降,进而MQ消息队列中的数据会快速增长导致积压,因此请务必在测试环境充分测试后,谨慎开启此功能。
采样
请参见全局配置下采样的介绍。
探针熔断
请参见全局配置下的探针熔断介绍。
错误及异常
请参见全局配置下的错误和异常的介绍。
事务
开启追踪
请参见全局配置下的开启追踪介绍。
事务命名
事务命名功能能够丰富事务的命名方式,包括根据请求方法来命名事务、根据请求URI(URI是指URL中除域名或IP地址、端口号、ContextPath和参数之外的部分)的部分来命名事务,或者根据请求的各种参数来命名事务。
命名原理:探针会根据配置好的匹配规则聚合符合条件的事务,再根据命名规则重新给事务进行命名,以方便您识别事务。
匹配规则
探针采集到一个请求后,会把请求和匹配规则进行匹配,符合同一匹配规则的请求就是同一类请求。
匹配规则中,应用探针对URL的匹配方式如下:
-
支持多种请求方式:GET、POST、PUT、DELETE、HEAD。
-
支持多样化的URI匹配方式:等于、开始于、结束于、包含、正则。
-
支持按照URL参数名、Header参数名和Body参数名匹配URL,该部分可根据用户的需要选择性配置。如果配置了多条参数规则,各规则必须都满足才匹配请求。
URL参数(适用于GET请求时):
请求头参数:
请求体参数(适用于POST请求时):
命名规则
命名规则使事务命名的方法更加丰富,既可以指定请求方式作为事务名称的一部分,也可以指定URI分段作为事务名称的一部分,还可以指定一些参数作为事务名称的一部分,从而增强事�务的可识别性。
如果仅指定匹配规则而不指定命名规则,那么符合条件的URL请求生成的事务的名称为事务命名规则名称。如果指定了命名规则,那么事务名称的结构为:
-
按请求方法命名:匹配规则名称/(请求方法)。
-
按URI分段命名:匹配规则名称/URI分段。
-
按URL参数名进行命名:匹配规则名称/?URL参数key=参数值。如果是多个参数,以&符号连接。
-
按Header参数名进行命名:匹配规则名称/?Header参数key=参数值。如果是多个参数,以&符号连接。
-
按Body参数名进行命名:匹配规则名称/?Body参数key=参数值。如果是多个参数,以&符号连接。
-
按Cookie参数名进行命名:匹配规则名称/?Cookie参数key=参数值。如果是多个参数,以&符号连接。
下面我们举例说明事务命名功能。
按请求方式命名举例
对于URI/portal/addchart这个事务,我们想对POST请求方式和GET请求方式进行的请求分别命名,所以就需要配置按请求方式命名,最终会生成test/(POST)和test/(GET)两个事务。
按URL命名举例
假设有URI/portal/addchart、URI/redirect/addchart多个类似的事务,我们只将POST方式下且URI的第3段为addchart的请求定义为操作,在配置匹配(聚合)规则时我们可以做如下配置:
最终生成的事务名称为test/addchart。
按URL参数命名举例
假设有请求/order,当action=1时代表提交订单,当action=2时代表支付,在配置规则时我们可以做如下配置(规则名为test):
通过上述聚合规则就会产生两个聚合的请求:
-
test?action=1
-
test?action=2
我们可以把第一类请求定义为提交订单的操作,把第二类请求定义为支付的操作。
按Header参数命名举例
假设对于/order这个事务,我们只对POST方式下的请求按照Header参数Referer进行命名,在配置规则时我们可以做如下配置(规则名为test):
当Referer为http://10.128.2.48:8080/server/system时,生成的事务名称为test?
Referer=http://10.128.2.48:8080/server/system。
按Body参数命名举例
假设对于/order这个事务,我们只对POST方式下的请求按照Body参数中action进行命名,在配置聚合规则时我们可以做如下配置(规则名为test):
当action为2时,生成的事务名称为test?action=2。
按Cookie参数命名举例
假设有请求https://10.128.2.45:8080/order,我们需要根据Cookie参数中的JSESSIONID参数进行命名:
在配置聚合规则时我们可以做如下配置(规则名为test):
那么,当JSESSIONID为1111时,生成的事务名称为test?JSESSIONID=1111。
事务追踪阈值
此处可针对已经发生过的具体事务单独设置追踪阈值。
NoSQL键值
通过在规则中设置以某字符串开头的键(Key),系统将会对涉及以该字符串开头的键的NoSQL操作名称进行聚合显示,格式为:操作+java*。例如,设置了键以“java”开头,那么操作名称会有如下显示:
事务过滤
事务过滤也可以称为事务/服务接口黑名单,即加入黑名单的事务/服务接口,系统不再收集其性能数据。
事务和服务接口的响应时间是影响应用评分的重要因素之一,大量的慢事务、慢服务接口会直接降低应用性能评分。但在一些特定场景下,例如长连接、批处理等已知的QPS高、响应时间长的慢事务,如果不希望它们的响应时间影响到应用评分,则可以通过配置过滤掉指定事务或服务接口,避免其对评分的影响。
添加需要过滤的事务或服务接口到右侧列表,单击提交即可,配置成功后不需要重启探针。勾选列表上方的事务复选框,列表中所有的事务会被选中;勾选列表上方的服务接口复选框,列表中所有的服务接口会被选中。
说明: 事务过滤仅Agent Collector 3.4.5及以上版本支持,服务接口过滤仅Agent Collector 3.5.3及以上版本支持。列表显示最近30分钟有数据的事务及服务接口,不包含聚合后的事务/服务接口,即聚合后的事务/服务接口不支持过滤。
热点方法
-
热点方法学习
探针默认监控的是基调听云研发人员根据支持的框架、协议、数据库驱动、MQ驱动等设置好的关键方法,对可能有性能瓶颈的方法进行嵌码,但不包括用户自己的业务逻辑代码。开启热点方法学习后,探针会自主学习应用中比较耗时的、调用比较频繁的方法,相应的方法会被嵌码,探针能够比正常情况下监测到更多的事务堆栈,最终展示在事务和后台任务的性能分解表格以及追踪详情中,性能分类中会增加“Hotspot”类别。默认为关闭状态。
-
白名单
用户可以添加指定的几个方法到白名单中,探针只自主学习白名单中的方法。
-
黑名单
探针不会自主学习黑名单中的方法。默认会显示Java基础包。
-
学习结果
学习次数越多,说明该方法被调用的频率越高,耗时也越长。学习次数前100名的方法将显示在学习结果列表中。对方法单击启用后,相应的方法会被嵌码,探针将采集性能数据,最终展示在事务、业务接口和后台任务的性�能分解表格以及追踪详情中。单击禁用后,探针将停止采集性能数据。单击删除后,相应的方法将从学习结果中删除。勾选选择前面的复选框可选择全部方法进行操作。
用户溯源
请参见系统配置下的用户溯源介绍。
自定义嵌码
请参见系统配置下的自定义嵌码介绍。
数据项
针对应用配置数据项时,可以关联具体的事务。当该事务发生慢追踪时,您可以在追踪详情中看到数据项页签。
自定义指标
请参见系统配置下的自定义指标介绍。
诊断工具
请参见系统配置的介绍。
实�例配置
实例设置可以对每个应用的每个独立实例进行配置管理,提供热点方法监控和探针熔断两个配置项,可以从应用级别继承配置值,也可以对特定的实例设置自己的配置项值。