CPU 分析
功能概述
CPU 分析功能为开发和运维团队提供应用程序 CPU 使用情况的实时监控和深度分析能力,帮助快速识别性能瓶颈、优化资源消耗,提升应用流畅度和用户体验。通过精准的 CPU 指标采集、异常检测和线程级分析,支撑应用性能持续优化和问题快速定位。
什么是 CPU 异常
CPU 异常是指应用在前台或后台一段时间内(30秒)持续高 CPU 消耗的情况。长时间的高 CPU 消耗会导致:
- 应用卡顿、响应变慢
- 设备发热明显
- 电池快速消耗
- 用户体验下降
核心价值
- 性能瓶颈识别:通过 CPU 使用率趋势和分位值分析,快速发现性能热点
- 线程级诊断:精确定位到具体线程和函数调用,为代码优化提供依据
- 用户体验保障:降低 CPU 消耗,提升应用流畅度,减少卡顿和 ANR
- 资源优化指导:为应用架构优化、算法改进提供数据支撑
使用场景
场景一:性能优化与发布前验证
新版本发布前,对比不同版本的 CPU 使用情况,确保性能优化生效,避免性能退化。
实践案例:
- 发现新版本 CPU 使用率 P90 值较上版本上升 20%
- 通过线程 CPU 分析定位到新增的图片处理逻辑
- 优化算法后 CPU 消耗降低 35%
场景二:线上问题快速定位
用户反馈应用卡顿或发热严重,通过 CPU 异常分析快速定位问题代码。
实践案例:
- 用户投诉应用使用时手机发热
- CPU 异常列表发现后台线程持续高 CPU
- 火焰图显示某个数据同步逻辑占用 60% CPU
- 修复后用户满意度提升 40%
场景三:多维度性能对比
对比不同设备、操作系统、业务场景下的 CPU 表现,针对性优化。
实践案例:
- 发现低端设备 CPU 使用率明显偏高
- 针对低端设备启用性能降级策略
- 低端设备卡顿率下降 50%
场景四:研发质量监控
建立 CPU 性能基线,通过异常次数和影响设备占比监控应用质量趋势。
实践案例:
- 设置 CPU 异常率基线为 < 2%
- 每日监控 CPU 异常趋势
- 发现异常时及时介入排查
技术实现原理
CPU 指标采集实现
iOS 平台
通过 iOS Mach 内核提供的系统调用获取 CPU 使用率:
技术特点
- 基于 Mach 内核 API,数据准确可靠
- 线程级粒度,支持精细化分析
- 系统级 API,性能开销低
Android 平台
通过读取 Linux 系统的 proc 文件系统获取 CPU 信息:
技术特点
- 基于 proc 文件系统,Linux 标准方式
- 支持进程和线程级别采集
- 轻量级实现,性能开销可控
CPU 使用率获取频率
首次采集
- SDK 启动后立即采集一次 App 和 Top 10 线程的 CPU 使用率
定期采集
- 后续每隔 1 分钟获取一次
- 持续监控 CPU 使用情况
Top 10 线程
- 定义:CPU 使用率排名前十的线程
- 用途:快速识别 CPU 消耗最大的线程
CPU 异常获取机制
采集频率
- 启动后每隔 5 秒采集一次(含第 0 秒)
- 持续采集最多 30 秒
采集内容
- App CPU 使用速率
- 超过线程 CPU 使用率阈值的线程堆栈
- 线程 CPU 使用率等信息
异常判定逻辑
1. 启动 CPU 异常监测(每 5 秒采集一次)
↓
2. 判断前两次采集的 App CPU 使用速率
↓
如果都小于异常阈值 → 终止监测(无异常)
↓
如果有一次超过阈值 → 继续采集到 30 秒
↓
3. 到达 30 秒后生成 CPU 异常�数据
采集要求
- 前两次采集作为快速判断,避免无效采集
- 持续 30 秒确保捕捉到真实的 CPU 异常
- 平衡监控效果和性能开销
数据上报机制
上报频率
- 每 1 分钟上传一次
失败处理
- 上传失败:缓存到本地
- 等待下个周期重试上传
- 上传成功:删除本地缓存
数据可靠性
- 确保数据不丢失(本地缓存)
- 避免重复上传(成功后删除)
- 减少网络开销(批量上传)
核心功能
1. 指标分析
过滤维度
支持多维度数据过滤,精准定位问题范围:
- 应用版本:对比不同版本的性能表现
- 设备型号:识别特定设备的性能问题
- 操作系统:分析系统版本对性能的影响
- 渠道来源:评估不同渠道用户的体验差异
- 业务场景:定位特定功能模块的性能瓶颈
趋势分析
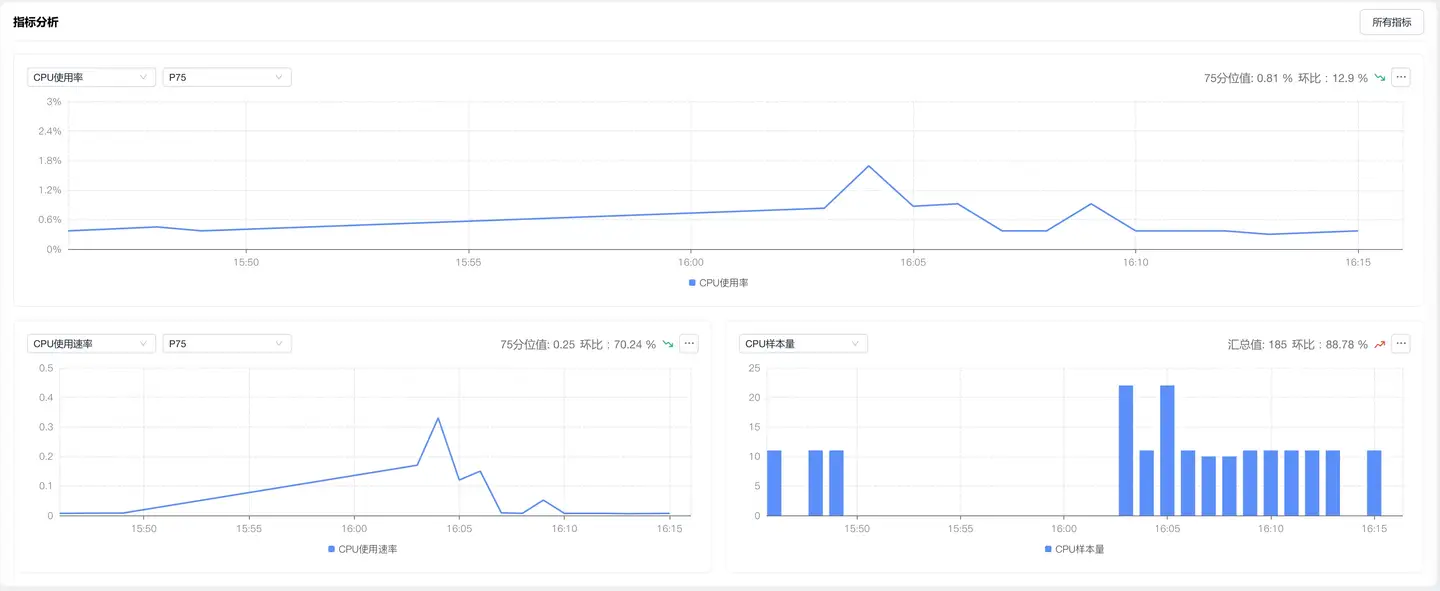
核心指标
| 指标 | 说明 | 计算公式 |
|---|---|---|
| CPU 使用率 | 指在一定时间间隔内,CPU 处理任务的时间与该时间间隔的总时间的比值 | 应用进程 CPU 时长 / 设备 CPU 核心频率时长 × 100% |
| CPU 使用速率 | 特定时间间隔内(1 分钟),应用进程消耗的 CPU 时间与采集时间的比率。对于多核系统来说,使用速率的最大值等于 CPU 核心数 | 应用进程 CPU 时长 / 采集时间 |
| 样本量 | 采集到的 CPU 数据样本数量 | - |
分位值分析
趋势图默认展示平均值,可切换查看不同分位值:
- P50(中位数):50% 用户的体验水平
- P90:关注长尾用户体验的关键指标
- P99:极端场景下的性能表现
最佳实践:建议重点关注 P90 和 P99 分位值,这些指标能更好地反映用户实际感知到的性能问题。
分布分析

按不同维度展示 CPU 指标分布,快速识别异常维度:
- 哪个版本的 CPU 消耗最高?
- 哪个设备型号性能最差?
- 哪个业务场景最耗资源?
数据导出:支持导出趋势和分布数据,用于离线分析和报告生成。
线程 CPU 使用率

功能说明
线程级 CPU 分析帮助开发团队精准定位到具体的性能瓶颈线程,为代码优化提供明确方向。
应用场景
- 主线程分析:识别主线程是否存在耗时操作,避免 UI 卡顿
- 后台线程优化:发现后台任务的 CPU 消耗,优化调度策略
- 线程泄漏排查:识别异常活跃或未正常销毁的线程
优化建议
- 主线程 CPU 使用率 > 80%:需将耗时操作移至后台线程
- 单个后台线程 CPU 使用率 > 50%:检查是否有死循环或计算密集型操作
- 线程数量过多:考虑使用线程池管理,避免线程创建开销
2. 异常分析
过滤条件
支持多维度过滤,快速定位问题范围:
- 基础维度:应用版本、设备、操作系统、渠道、业务场景
- 异常维度:异常堆栈、异常 ID、异常类型、异常状态
- 管理维度:userID、处理人、标签
趋势分析

异常指标体系
| 指标 | 说明 | 计算公式 |
|---|---|---|
| 异常次数 | 触发 CPU 异常的总次数 | 30 秒内 CPU 使用速率超过阈值记为一次异常 |
| 异常率 | CPU 异常占应用启动的比例 | CPU 异常次数 / 总启动次数 |
| 影响设备数 | 发生 CPU 异常的唯一设备数 | 去重统计 |
| 影响设备占比 | 受影响设备的比例 | 发生 CPU 异常的设备数 / 总活跃设备数 |
异常分析策略
- 异常率上升:可能是代码缺陷或性能退化,需优先处理
- 影响设备占比高:说明问题普遍性强,影响面广
- 异常次数突增但设备占比低:可能是特定场景或设备的问题
数据导出:支持导出异常趋势数据,用于性能报告和问题追踪。
异常列表

功能说明
异常列表按高频调用栈和线程名自动聚合归类,将相同根因的问题归为一组,避免重复排查。
关键特性
- 智能聚合:相同调用栈的异常自动归类,减少问题数量
- 符号化支持:上传 DSYM(iOS)/ Mapping 文件(Android) 实现堆栈符号化/反混淆
- 过滤筛选:支持异常堆栈、异常 ID、userID、处理人、标签等多维度过滤
- 数据导出:支持导出异常列表,用于问题跟踪和归档
处理流程建议
- 优先级排序:按影响设备数或异常次数排序,优先处理高频问题
- 分配处理人:标记处理人,明确责任
- 添加标签:分类标记(如:性能优化、代码缺陷、第三方库问题)
- 跟踪状态:标记异常状态(待处理、处理中、已修复、已忽略)
异常详情
概览

概览信息
- 异常基本信息:异常 ID、首次/最后发生时间、影响版本
- 影响范围:影响设备数、异常次数、异常率
- 典型样本:选择代表性样本进行深度分析
- 趋势变化:异常发生的时间趋势
异常分享:支持生成异常详情链接,便于团队协作和问题讨论。
单样本调用树
设备详情

展示异常发生时的完整上下文信息:
- 设备环境:设备型号、操作系统版本、内存、CPU 信息
- 应用状态:应用版本、前台/后台状态、运行时长
- 网络环境:网络类型、运营商
- 用户信息:userID、会话 ID
调试提示:结合设备详情可判断问题是否与特定设备或环境相关。
堆栈详情
提供两种堆栈分析视图:
1. 火焰图

火焰图以可视化方式展示线程堆栈信息,宽度表示 CPU 占用时间:
- 横轴(宽度):函数占用的 CPU 时间,越宽占用越多
- 纵轴(高度):函数调用栈的深度
- 颜色:区分用户代码和系统代码
使用技巧
- 节点搜索:快速定位特定函数或类
- 筛选过滤:
- 仅显示用户代码:关注应用自身问题
- 仅显示系统代码:分析系统调用开销
- 热点识别:宽度最大的节点即为 CPU 热点
2. 线程调用树
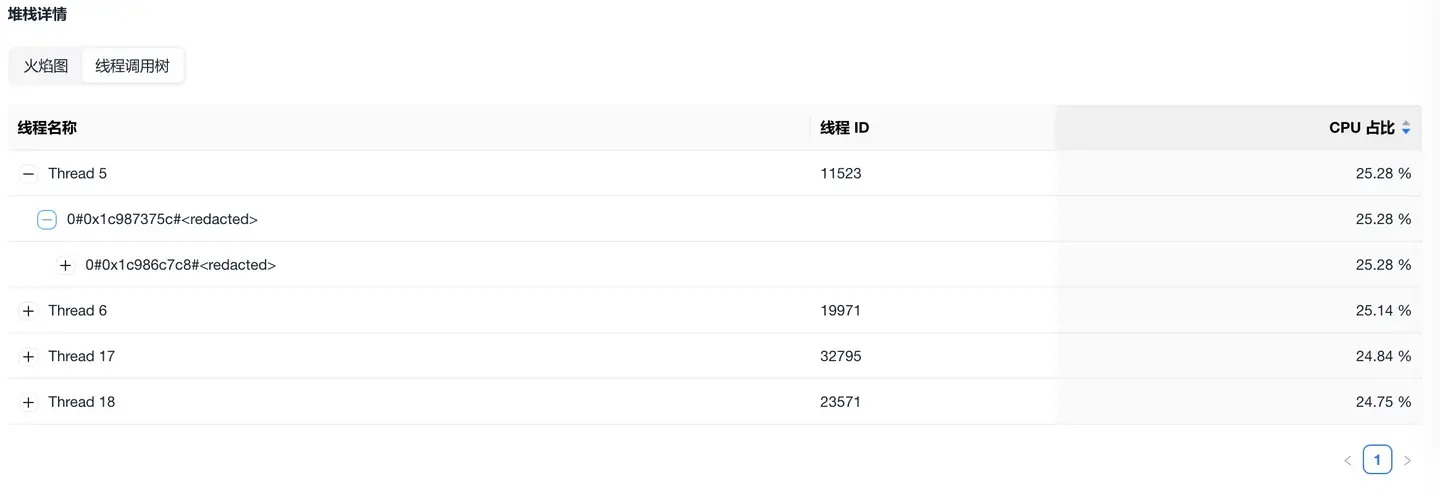
调用树以树形结构展示线程调用关系:
- CPU 占比:线程 CPU 使用率 / 应用 CPU 使用率
- 自顶向下:从线程入口到具体函数的调用链路
- 展开分析:逐层展开查看详细函数调用
分析方法
- 按 CPU 占比排序,优先分析占比最高的线程
- 展开调用树,定位到具体的耗时函数
- 结合代码逻辑,分析是否存在优化空间
汇总调用树

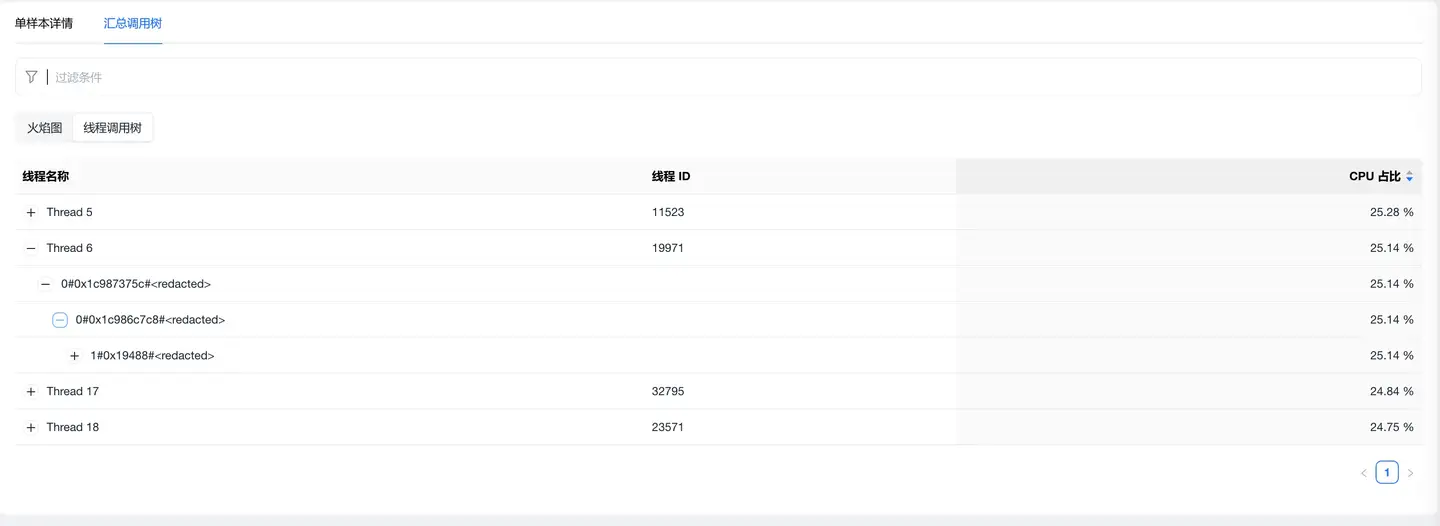
功能说明
将同一异常问题的所有样本数据聚合展示,呈现问题的整体特征:
- 火焰图汇总:所有样本的 CPU 消耗聚合,识别共性热点
- 调用树汇总:多个样本的调用路径聚合,发现通用调用模式
应用价值
- 模式识别:发现异常问题的共同特征
- 优化验证:对比优化前后的汇总数据,验证效果
- 根因确认:通过多样本聚合,更准确地定位根因
CPU 异常阈值设置

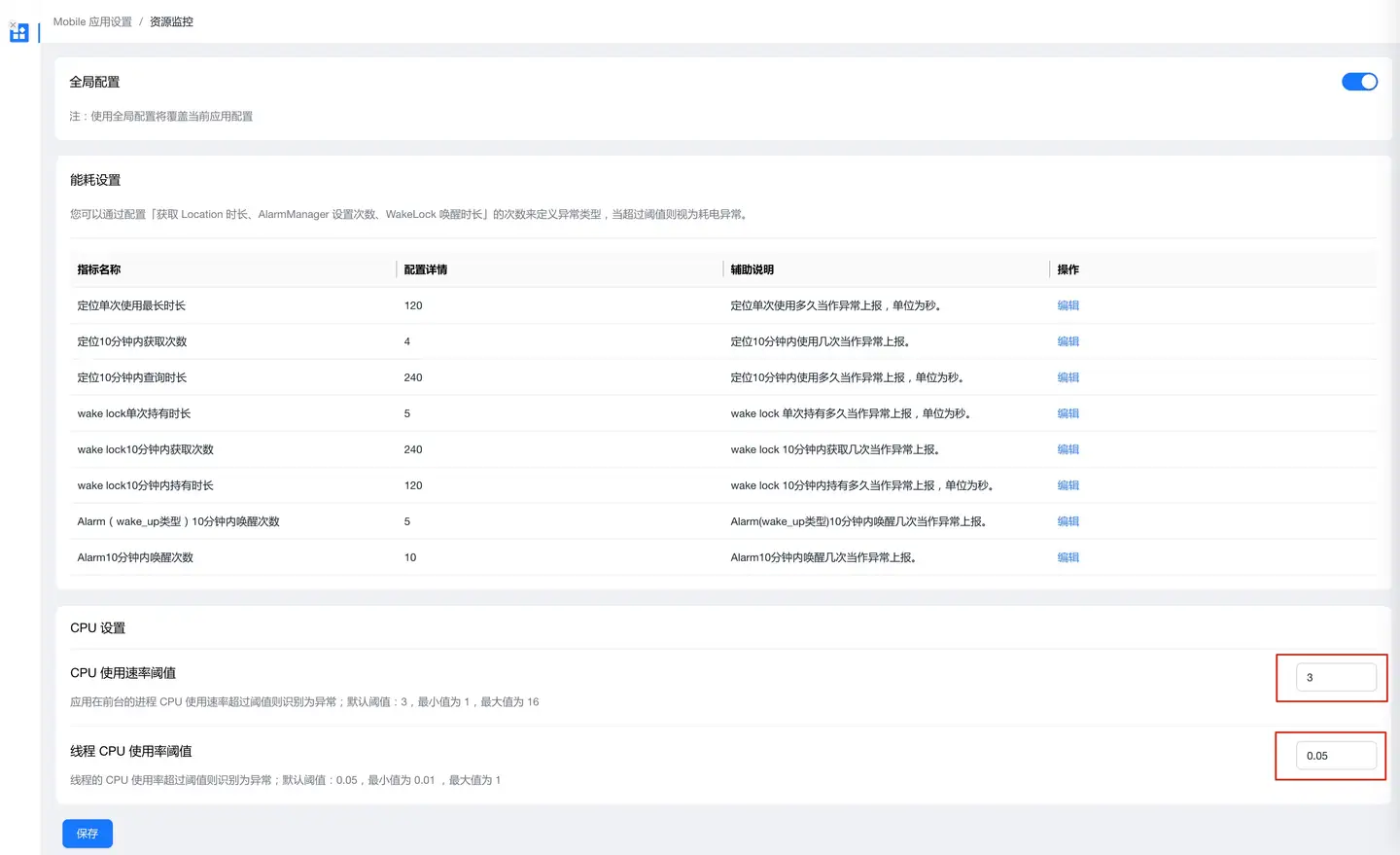
设置路径:应用列表 → 设置 → 资源监控 → CPU 设置
阈值配置建议
根据应用类型和性能目标,合理设置 CPU 异常阈值:
| 应用类型 | 前台阈值建议 | 后台阈值建议 | 说明 |
|---|---|---|---|
| 轻量级应用(工具类) | 60% - 70% | 30% - 40% | 功能简单,CPU 消耗应较低 |
| 中度应用(社交、电商) | 70% - 80% | 40% - 50% | 有一定交互和数据处理 |
| 重度应用(游戏、视��频) | 80% - 90% | 50% - 60% | 渲染和计算需求较高 |
阈值调整策略
- 建立基线:先使用默认阈值运行一段时间,收集数据
- 分析分布:查看 CPU 使用率的分位值分布
- 合理设定:
- 阈值过低:误报过多,增加排查成本
- 阈值过高:遗漏真实性能问题
- 建议:设置在 P90 - P95 之间
- 持续优化:随着应用优化,逐步降低阈值,提升性能标准
性能优化指南
常见 CPU 性能问题
问题一:主线程高 CPU 占用
现象:主线程 CPU 使用率持续 > 80%,应用卡顿
常见原因
- 主线程执行大量计算或 I/O 操作
- 频繁的 UI 刷新和布局计算
- 同步网络请求阻塞主线程
- 大量对象创建和销毁
优化建议
- 将耗时操作移至后台线程(网络请求、文件 I/O、数据处理)
- 优化布局层级,减少 measure/layout 次数
- 使用异步加载和懒加载策略
- 避免在主线程进行复杂计算
问题二:后台线程 CPU 异常
现象:应用退到后台后仍有高 CPU 消耗
常见原因
- 后台数据同步未停止
- 定时器或循环任务未取消
- 后台线程未正确清理
- 第三方 SDK 持续运行
优化建议
- 应用进入后台时暂停非必要任务
- 取消定时器和循环任务
- 合理使用后台任务 API
- 审查第三方 SDK 的后台行为
问题三:特定业务场景 CPU 峰值
现象:某个功能触发时 CPU 使用率突增
常见原因
- 大数据量处理未优化
- 算法复杂度过高
- 频繁的对象创建和 GC
- 图片/视频处理逻辑不合理
优化建议
- 优化算法复杂度(使用更高效的数据结构)
- 分批处理大数据量,避免一次性处理
- 对象复用,减少 GC 压力
- 使用硬件加速(GPU)处理图像和视频
性能优化流程
1. 发现问题
↓ 通过 CPU 异常率、趋势分析发现异常
2. 定位范围
↓ 使用多维度过滤,缩小问题范围
3. 分析根因
↓ 火焰图/调用树定位具体代码
4. 制定方案
↓ 基于分析结果设计优化方案
5. 验证效果
↓ 对比优化前后的 CPU 指标
6. 持续监控
↓ 建立性能基线,持续追踪
最佳实践
1. 建立性能基线
为什么需要基线
- 对比不同版本的性能变化
- 量化优化效果
- 及时发现性能退化
如何建立基线
- 选择稳定版本作为基线版本
- 记录关键指标:CPU 使用率 P50/P90/P99、异常率、影响设备占比
- 按维度分别建立基线(设备、系统、场景)
- 定期(每版本)对比基线数据
2. 分层性能监控
应用层监控
- 关注整体 CPU 使用率和异常率
- 监控核心业务场景的性能表现
线程层监控
- 重点关注主线程和核心业务线程
- 识别异常活跃的后台线程
函数层监控
- 通过火焰图和调用树分析热点函数
- 定期 review 高频调用的函数性能
3. 性能测试集成
开发阶段
- 本地性能测试:使用 Profiler 工具进行 CPU 分析
- 单元测试:为性能敏感的函数编写性能测试用例
测试阶段
- 压力测试:模拟高并发场景测试 CPU 表现
- 兼容性测试:在不同设备上验证性能
- 回归测试:每个版本对比 CPU 基线
发布阶段
- 灰度发布:小范围观察 CPU 指标
- 全量发布:持续监控 CPU 异常率
常见问题 FAQ
Q1:为什么 CPU 使用率和使用速率数据不一致?
A:这是正常现象,两个��指标的计算维度不同:
- CPU 使用率:相对设备总 CPU 核心频率的占比,最大值 100%
- CPU 使用速率:实际消耗的 CPU 时间,多核设备最大值等于核心数(如 8 核设备最大为 8)
建议:
- 单核场景:两个指标基本一致
- 多核场景:使用速率更能反映实际 CPU 消耗
Q2:如何判断 CPU 使用率多高算异常?
A:需要结合应用类型和场景判断:
| 场景 | 合理范围 | 需要关注 | 异常 |
|---|---|---|---|
| 前台空闲 | < 20% | 20% - 40% | > 40% |
| 前台交互 | 20% - 50% | 50% - 70% | > 70% |
| 后台运行 | < 10% | 10% - 30% | > 30% |
| 游戏/视频 | 40% - 80% | 80% - 90% | > 90% |
Q3:如何上传符号表文件进行堆栈符号化?
A:符号化步骤:
iOS 应用(DSYM 文件)
- 在 Xcode 编译时生成 DSYM 文件
- 进入应用设置 → 符号表管理
- 上传对应版本的 DSYM 文件
- 系统自动对新采集的堆栈进行符号化
Android 应用(Mapping 文件)
- 在 ProGuard/R8 混淆时生成 mapping.txt
- 进入应用设置 → 符号表管理
- 上传对应版本和渠道的 mapping 文件
- 系统自动对混淆堆栈进行反混淆
提示:建议在发布版本后立即上传符号表,以便及时分析线上问题。
Q4:CPU 异常数据采集会影响应用性能吗?
A:影响极小,SDK 已做充分优化:
- 采样策略:不是持续采集,而是智能采样
- 异步处理:数据处理在独立线程,不阻塞主线程
- 性能开销:CPU 开销 < 1%,内存开销 < 2MB
- 可控开关:可通过远程配置调整采集频率
性能测试数据:
- 开启 CPU 监控:应用性能影响 < 0.5%
- 堆栈采集开销:单次 < 10ms
Q5:如何处理第三方 SDK 导致的 CPU 异常?
A:处理策略:
- 识别问题:通过堆栈分析确认是第三方 SDK 问题
- 评估影响:统计该问题的影响��范围和严重程度
- 联系厂商:向 SDK 厂商反馈问题,索取解决方案
- 临时方案:
- 降级使用:关闭耗资源的功能
- 延迟初始化:避免启动时初始化
- 条件加载:仅在需要时加载 SDK
- 长期方案:
- 替换 SDK:选择性能更好的替代方案
- 自研实现:核心功能考虑自研