概览
功能概述
概览是 Mobile RUM 的核心入口,提供应用整体健康状况的全局视图。通过应用评分、核心指标趋势、关系等维度,帮助团队快速了解应用性能表现、定位问题根因、评估用户体验。
访问路径:��应用列表 → 点击应用名称 → 概览页面
核心价值
- 一站式健康检查:通过评分快速判断应用整体质量
- 问题快速发现:核心指标趋势识别性能异常
- 全链路可视化:端到端关系定位性能瓶颈
- 数据驱动决策:量化指标支撑优化和发布决策
应用评分

评分体系
应用评分综合 8 个核心性能指标计算得出,反映应用整体质量:
| 指标维度 | 权重占比 | 指标说明 |
|---|---|---|
| 崩溃率 | 20% | 应用稳定性的核心指标 |
| 卡顿率 | 15% | 应用流畅度的关键体现 |
| 请求错误率 | 10% | 网络请求可用性 |
| 请求耗时 | 15% | 网络请求性能 |
| 首屏耗时 | 10% | 页面加载体验 |
| 启动时间 | 15% | 应用启动体验 |
| 可交互时间 | 5% | 页面交互就绪时间 |
| �操作时间 | 10% | 用户操作响应速度 |
评分展示
左侧饼图
- 直观展示应用总分(0-100分)
- 不同颜色代表不同性能指标的贡献度
- 鼠标悬停查看每个指标的详细信息
右侧指标列表
- 展示 8 个性能指标的当前值
- 环比数据(与上一时间段对比)
- 快速识别性能趋势(上升/下降)
饼图弹窗说明

悬停在饼图上显示详细信息:
- 第一行:性能指标名称
- 第二行:为应用评分提供的加分
- 第三行:该指标自身的得分
- 第四行:该指标的实际数值
评分应用场景
日常监控
- 每日查看评分变化,及时发现质量问题
- 评分下降时快速定位是哪个指标恶化
版本发布
- 发布前对比新旧版本评分
- 评分下降超过 5 分需重点关注
性能优化
- 评估优化效果的量��化指标
- 优化后评分提升证明效果
指标分析
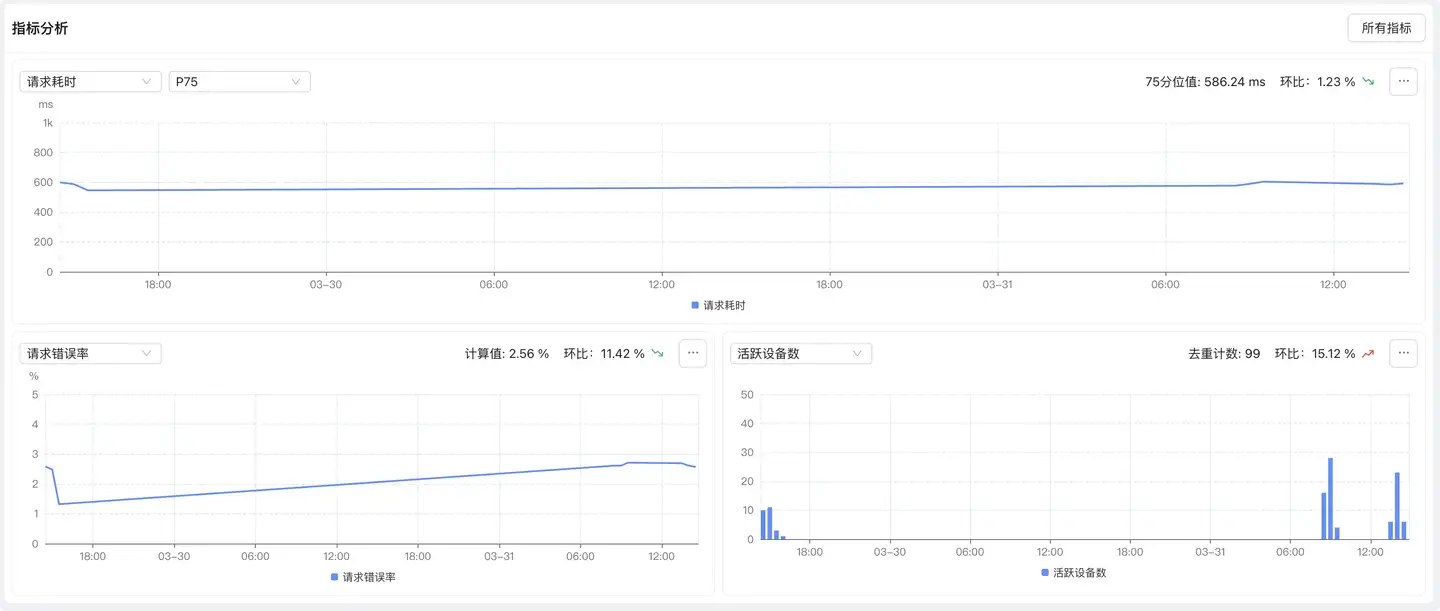
趋势图分析
展示核心性能指标随时间的变化趋势,支持多指标对比。
支持的指标
- 性能指标:启动时间、首屏耗时、页面加载耗时、操作时间、请求耗时
- 异常指标:崩溃率、卡顿率、请求错误率
- 业务指标:活跃设备数、启动次数、操作次数、请求次数
分位值分析
耗时类指标支持多种统计方式:
- 平均值(AVG):所有样本的平均值
- P50(中位数):50% 用户的体验水平
- P75(默认):75% 用户的体验水平,平衡整体和长尾
- P95:95% 用户的体验水平,关注长尾用户
- P99:99% 用户的体验水平,极端场景性能
最佳实践:P75 看整体趋势,P95/P99 看长尾问题。
所有指标
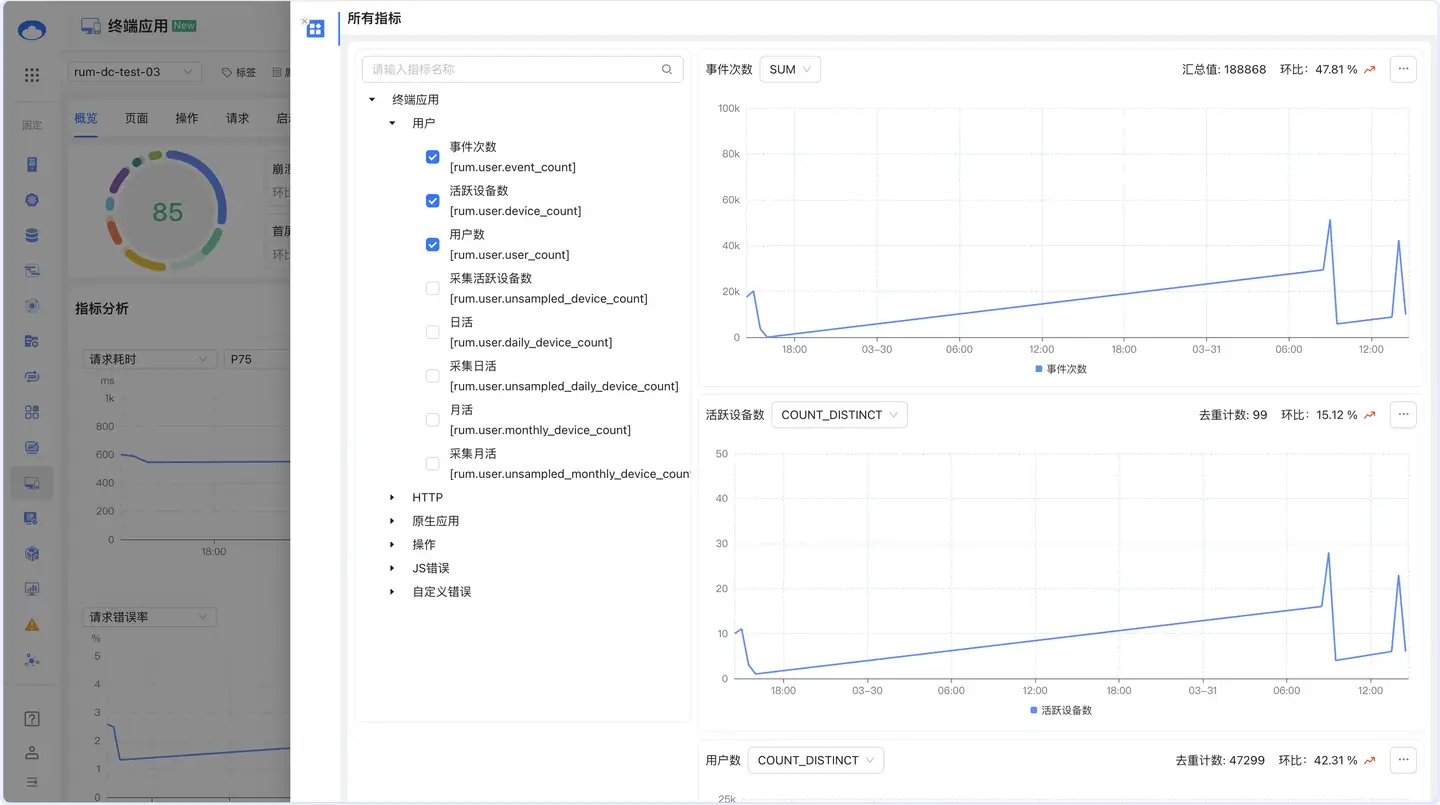
点击右侧【所有指标】按钮,进入指标体系页面:
功能特性
- 展示所有可用指标的属性信息
- 支持指标搜索,快速定位
- 查看指标定义、计算方式、单位
- 了解指标的业务含义
应用场景
- 了解平台提供的完整指标体系
- 自定义仪表盘时选择合适的指标
- 理解指标含义,准确分析数据
关系
关系以可视化方式展示应用的端到端性能链路,帮助快速定位性能瓶颈。
页面
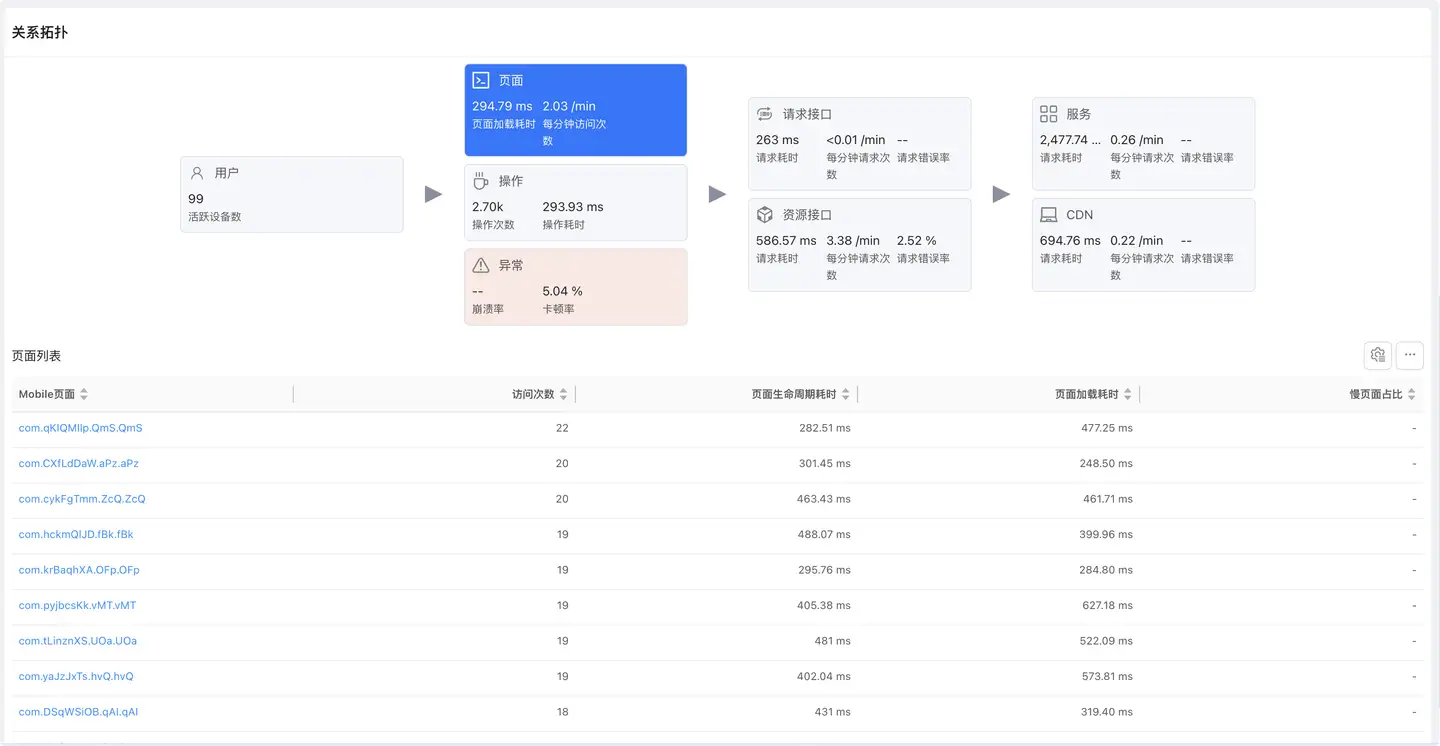
展示应用所有页面的性能数据,识别慢页面。
列表字段
- Mobile 页面:页面名称(Activity/ViewController)
- 访问次数:页面被访问的总次数
- 页面生命周期耗时:页面从创建到销毁的时间
- 页面加载耗时:页面内容加载完成的时间
- 慢页面占比:加载耗时超过阈值的页面占比
快速定位
- 按慢页面占比排序,优先优化高占比页面
- 按访问次数排序,优先优化高频页面
- 点击页面名称查看详细分析
详情入口:点击页面名称 → 页面详情分析
操作
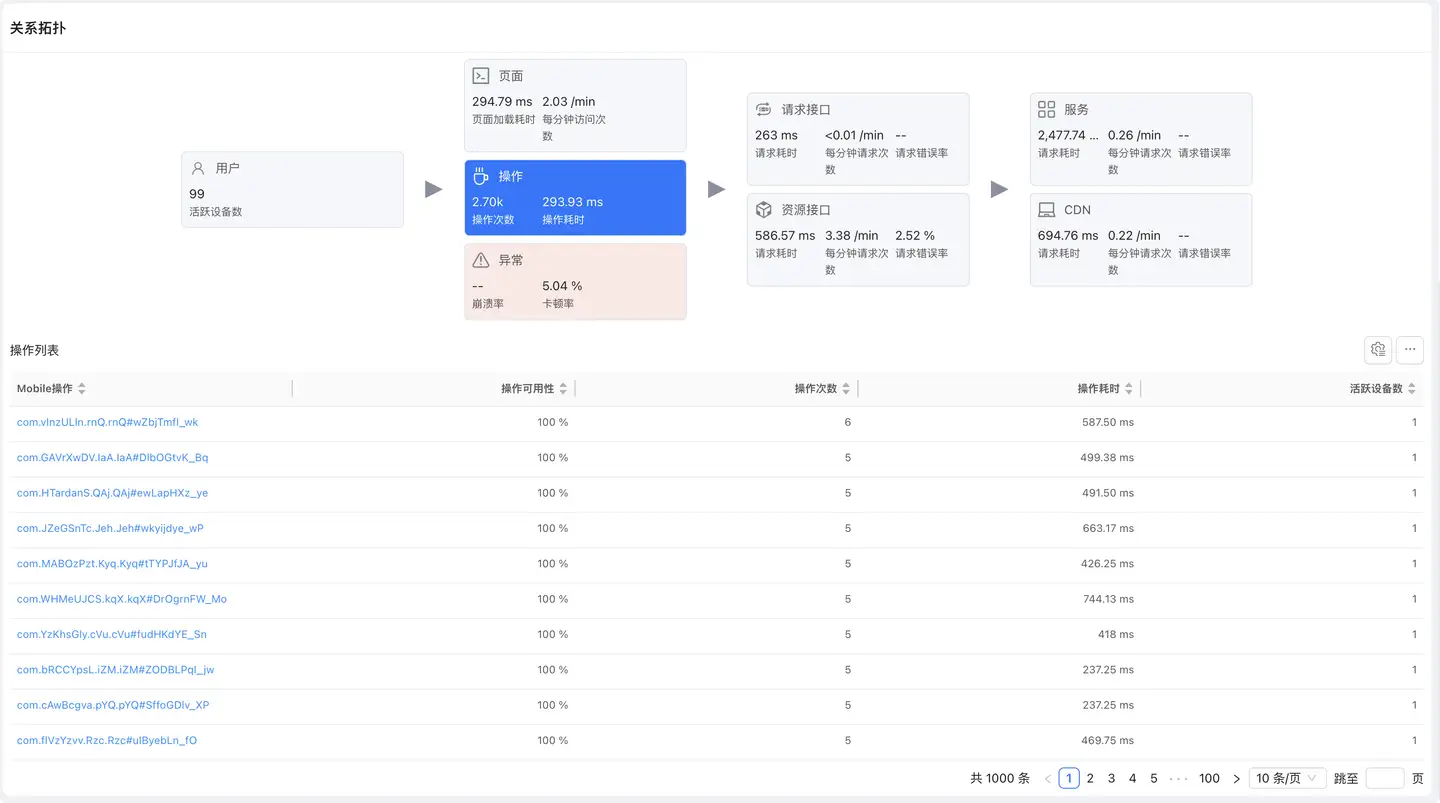
展示用户操作行为的性能和可用性数据。
列表字段
- Mobile 操作:操作名称(方法名/控件 ID)
- 操作可用性:操作成功执行的比例
- 操作次数:操作被执行的总次数
- 请求次数:操作触发的网络请求数
- 平均请求次数:每次操作平均发起的请求数
- 活跃设备数:执行该操作的设备数
- 请求错误率:操作中请求失败的比例
- 慢操作占比:操作耗时超过阈值的占比
- 每分钟操作次数:操作频率
- 失败操作次数:操作失败的总次数
- 失败操作人数:操作失败影响的用户数
- 操作失败率:操作失败的比例
分析要点
- 操作可用性 < 99%:优先排查失败原因
- 慢操作占比 > 10%:需要性能优化
- 失败操作影响用户多:影响业务转化
详情入口:点击操作名称 → 操作详情分析
异常
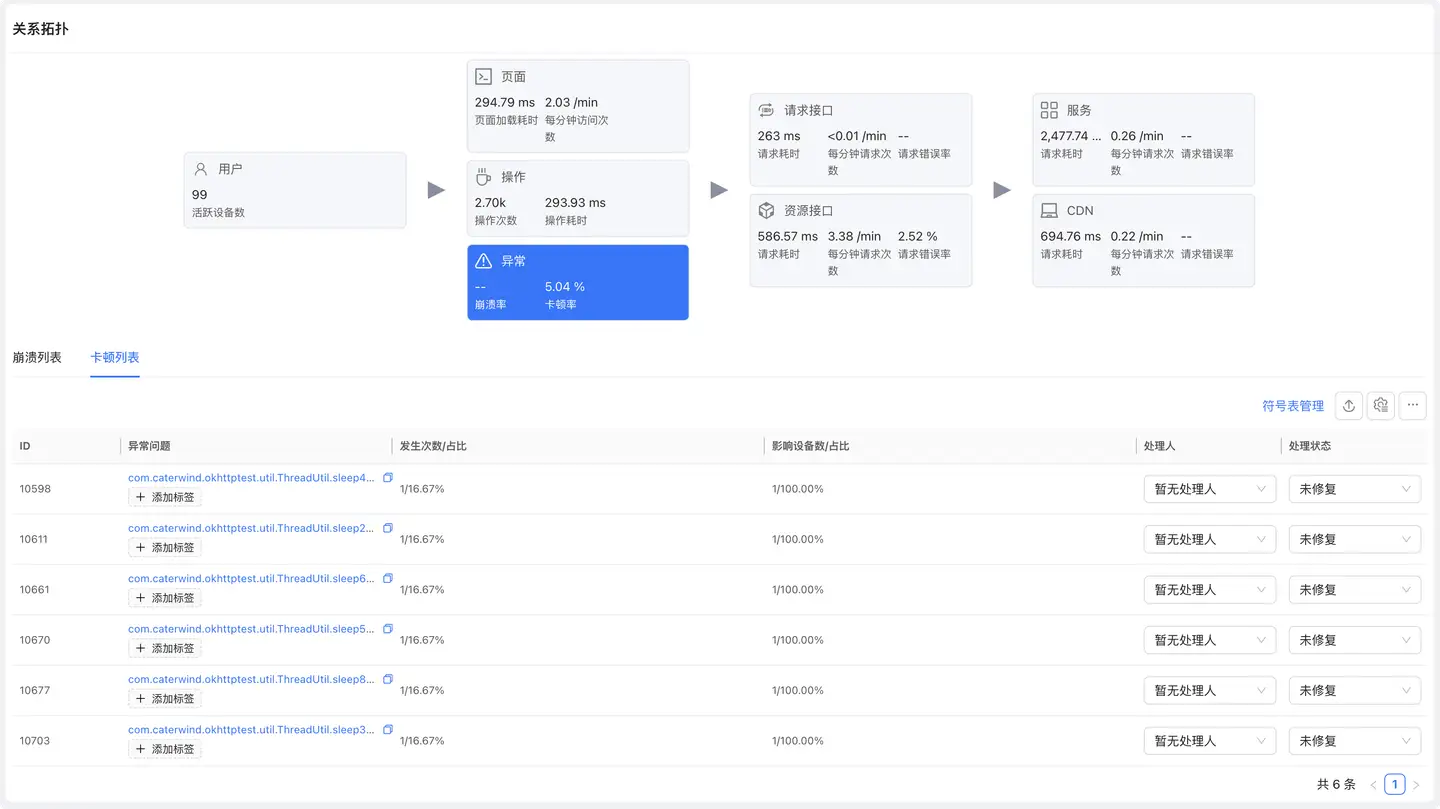
展示崩溃和卡顿异常的汇总信息。
列表字段
- 异常 ID:异常的唯一标识
- 异常问题:异常的堆栈信息(归类后)
- 版本:出现异常的应用版本
- 发生次数/占比:异常发生的次数和占比
- 影响设备数/占比:受影响的设备数量和占比
- 处理人:负责处理�该异常的人员
- 处理状态:待处理/处理中/已修复/已忽略
功能特性
- 支持导出异常列表
- 支持自定义表头
- 按影响范围排序,优先处理高影响问题
详情入口:点击异常问题 → 异常详情分析
请求接口
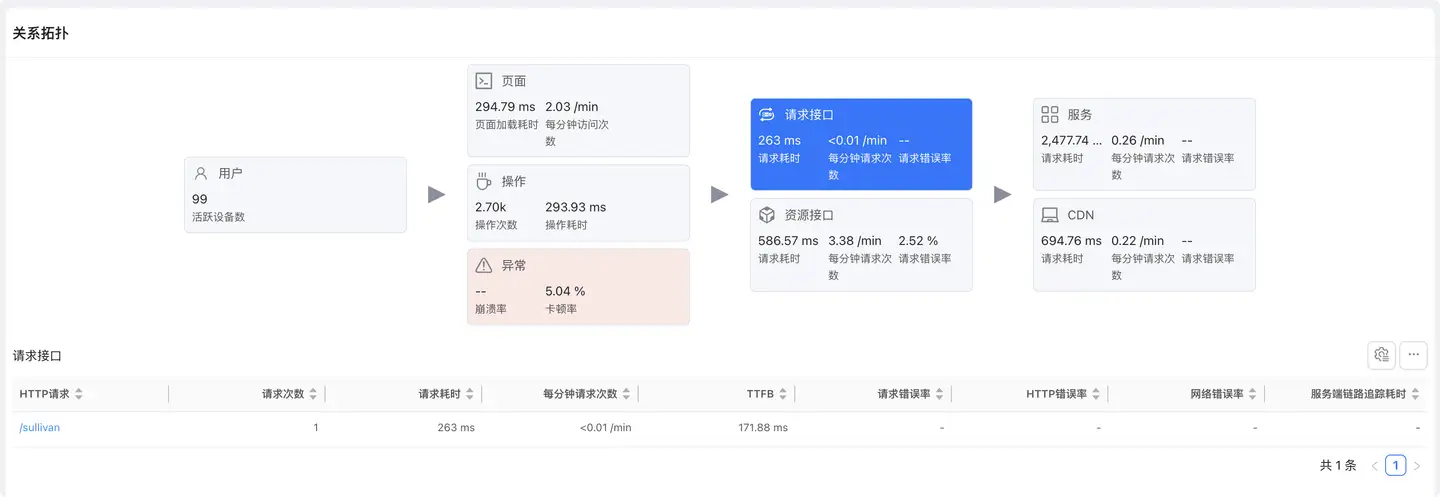
展示数据类请求(mime-type 为 text 或 json)的性能数据。
列表字段
- HTTP 请求:请求 URL
- 请求次数:请求被调用的总次数
- 请求耗时:请求的平均响应时间
- 每分钟请求次数:请求频率(RPM)
- TTFB:首字节时间(Time To First Byte)
- 请求错误率:HTTP 错误 + 网络错误的比例
- 网络错误率:网络层错误(DNS、连接、超时)
- 服务端链路追踪耗时:后端服务处理时间
- 慢请求次数/占比:超过阈值的请求数量和占比
- DNS/TCP/SSL 耗时:网络各阶段耗时
- 服务端响应耗时:后端处理时间
- 剩余包耗时:数据传输时间
- 服务端链路追踪错误率:后端服务错误率
- 上行/下行流量消耗:数据传输量
- 可用性:请求成功率
分析方向
- 请求耗时高:查看是网络层还是服务端问题
- 错误率高:区分 HTTP 错误和网络错误
- 慢请求多:评估接口优化或降级
详情入口:点击 HTTP 请求 → 请求详情分析
�资源接口
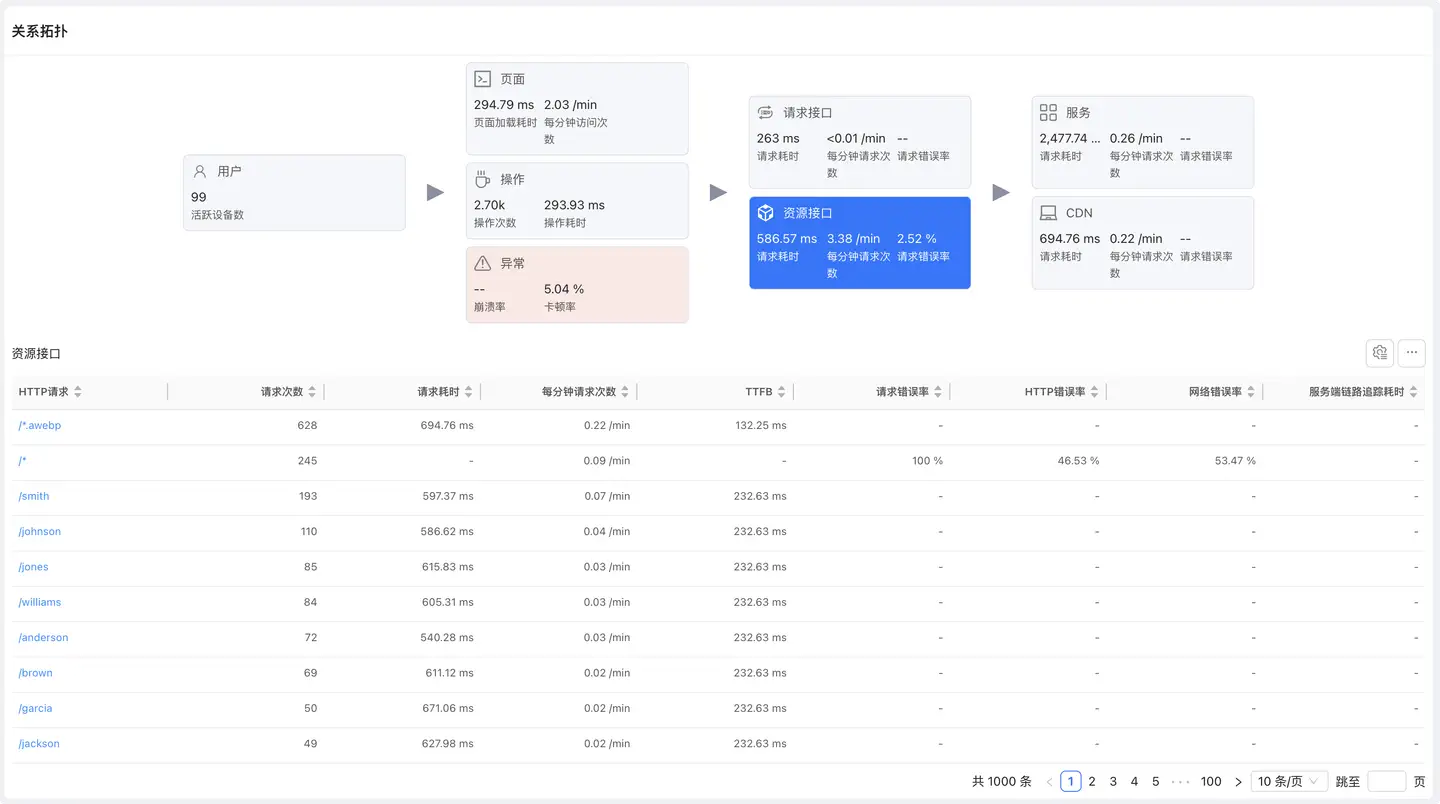
展示静态资源(图片、JS、CSS 等)的加载性能数据。
列表字段
- 与请求接口相同的字段
- 重点关注资源加载耗时和传输数据量
分析重点
- 资源加载慢:影响页面渲染速度
- 传输数据量大:优化图片压缩、代码分包
- 可用性低:检查 CDN 或资源服务器
详情入口:点击 HTTP 请求 → 请求详情分析
服务
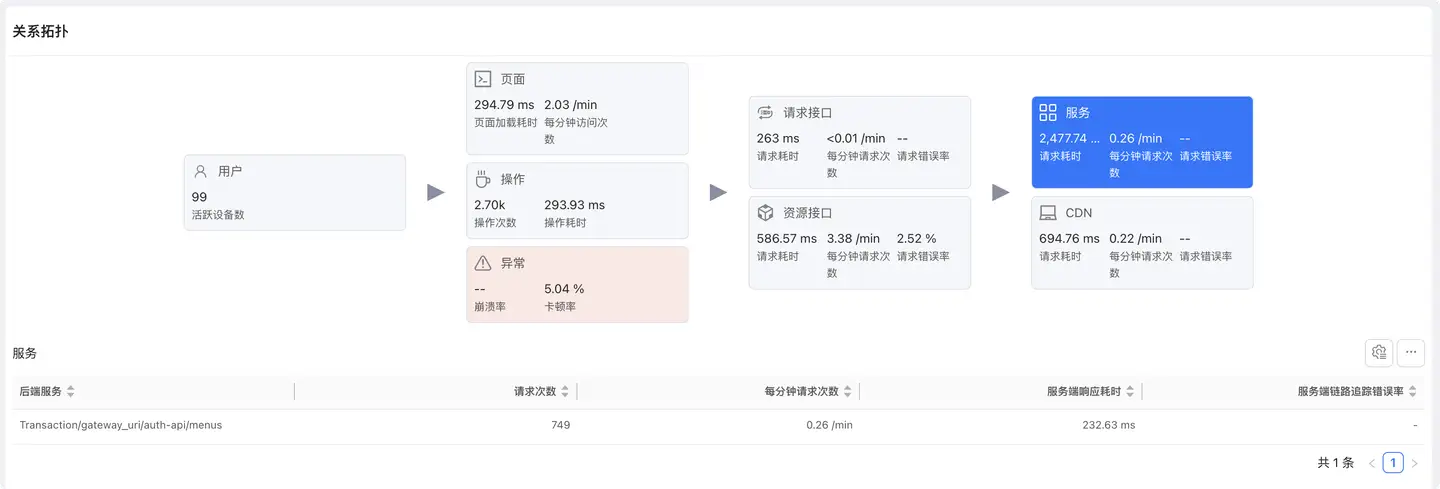
展示后端服务的性能数据(需后端嵌入 APM 探针)。
列表字段
- 后端服务:服务名称
- 请求次数:调用服务的总次数
- 每分钟请求次数:服务调用频率
- 服务端响应耗时:服务处理时间
- 服务端链路追踪错误率:服务错误率
价值
- 打通前后端,实现全链路追踪
- 定位问题是在客户端、网络还是服务端
- 评估后端优化对用户体验的影响
提示:需要后端应用嵌入基调听云 APM 探针才能采集服务端数据。
CDN
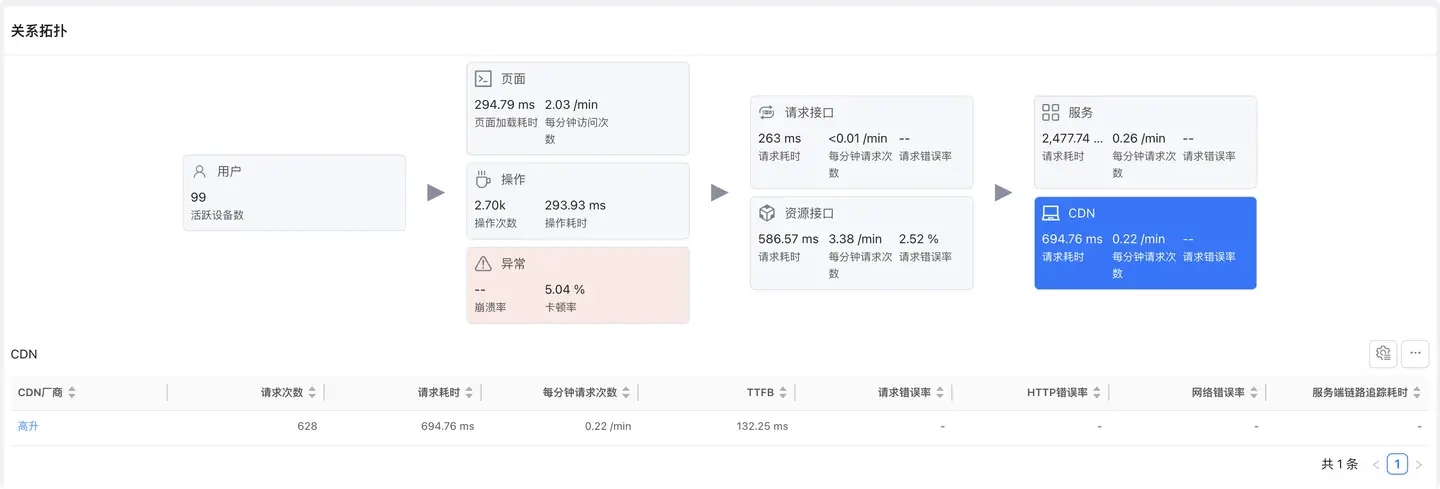
展示各 CDN 厂商的性能表现。
列表字段
- CDN 厂商:CDN 供应商名称
- 与请求接口相同的性能指标
应用场景
- 对比不同 CDN 厂商的性能
- 评估 CDN 对用户体验的影响
- 优化 CDN 选型和配置策略
详情入口:点击 CDN 厂商 → CDN 详情分析
完整功能导航
概览提供了快速跳转到各功能模块的入口,以下是完整的功能列表:
用户体验分析
| 功能 | 说明 | 入口 |
|---|---|---|
| 页面分析 | 页面性能和用户行为分析 | 关系 → 页面 或 顶部菜单 |
| 操作分析 | 用户操作性能和体验分析 | 关系 → 操作 或 顶部菜单 |
| 启动分析 | 冷启动、热启动性能分析 | 顶部导航 → 启动 |
| 流畅度分析 | FPS 和丢帧评分分析 | 顶部导航 → 流畅度 |
网络性能分析
| 功能 | 说明 | 入口 |
|---|---|---|
| 请求分析 | HTTP 请求性能和错误分析 | 关系 → 请求接口/资源接口 或 顶部菜单 |
| CDN 分析 | CDN 性能对比和优化 | 关系 → CDN 或 顶部菜单 |
| 协议扩展 | WebSocket、gRPC 等协议监控 | 顶部导航 → 协议扩展 |
异常与稳定性
| 功能 | 说明 | 入口 |
|---|---|---|
| 异常分析 | 崩溃、卡顿、ANR 等异常分析 | 关系 → 异常 或 顶部菜单 |
| OOM 分析 | 内存溢出问题分析 | 顶部导航 → OOM |
| 大对象分析 | 大对象内存占用和泄漏分析 | 顶部导航 → 大对象 |
资源与性能
| 功能 | 说明 | 入口 |
|---|---|---|
| CPU 分析 | CPU 使用率和异常分析 | 顶部导航 → CPU |
| 能耗分析 | 电量消耗和能耗优化 | 顶部导航 → 能耗 |
用户与版本
| 功能 | 说明 | 入口 |
|---|---|---|
| 用户统计 | 用户规模、活跃度、增长趋势 | 顶部导航 → 用户统计 |
| 用户追踪 | 单个用户的完整行为轨迹 | 顶部导航 → 用户追踪 |
| 版本分布 | 版本性能对比和质量评估 | 顶部导航 → 版本分布 |
使用建议
日常监控
每日巡检流程
- 查看应用评分,识别整体质量变化
- 查看指标趋势,发现异常波动
- 查看异常列表,处理新增问题
- 查看慢页面/操作,优化用户体验
关注重点
- 评分下降 > 5 分
- 崩溃率/卡顿率突增
- 慢页面/操作占比上升
- 请求错误率异常
版本发布
发布前检查
- 对比新旧版本评分
- 检查核心指标是否退化
- 验证关键页面和操作性能
- 确认无新增严重异常
发布后监控
- 实时监控评分和核心指标
- 对比发布前后数据
- 快速响应异常问题
- 评估发布效果
性能优化
问题定位流程
- 概览发现问题(评分下降、指标异常)
- 关系定位范围(页面、操作、请求)
- 详情分析找到根因(Trace、堆栈、设备)
- 制定优化方案
- 验证优化效果(对比数据)
优化优先级
- P0:崩溃、严重卡顿、核心功能不可用
- P1:慢页面、慢操作、高频请求优化
- P2:长尾问题、低频场景优化
- P3:体验提升、预防性优化
数据分析技巧
多维度分析
- 按版本:定位问题引入版本
- 按设备:识别特定设备问题
- 按地域:发现区域性问题
- 按时间:分析业务高峰影响
趋势分析
- 短期趋势:日/周波动,快速响应
- 长期趋势:月/季变化,战略规划
- 突变分析:异常突增,紧急处理
- 周期分析:业务高峰,容量规划
常见问题 FAQ
Q1:评分突然下降如何排查?
A:系统化排查流程:
-
查看评分详情
- 鼠标悬停在饼图上
- 找出哪个�指标评分下降最多
-
查看指标趋势
- 进入指标分析
- 查看该指标的时间趋势
- 确认下降的时间点
-
定位问题范围
- 按版本过滤:是否新版本引入
- 按地域过滤:是否特定地区
- 按设备过滤:是否特定设备
-
深入分析根因
- 进入对应功能详情(如崩溃分析、慢页面分析)
- 查看具体问题和堆栈信息
- 制定修复方案
Q2:如何判断性能是否正常?
A:从三个维度评估:
1. 绝对值评估
- 应用评分 > 80 分:健康
- 应用评分 70-80 分:需关注
- 应用评分 < 70 分:需优化
2. 趋势评估
- 评分持续上升:优化有效
- 评分基本稳定:运行正常
- 评分持续下降:需要介入
3. 对比评估
- 环比变化 < 5%:正常波动
- 环比变化 5%-10%:需要关注
- 环比变化 > 10%:异常,需排查
Q3:关系如何使用?
A:关系用于端到端性能分析:
使用场景
- 问题定位:页面慢 → 查看页面调用的请求 → 定位慢请求
- 影响评估:某个请求慢 → 查看影响的页面和操作
- 优化验证:优化后查看关联模块的性能变化
分析路径
- 自顶向下:页面 → 操作 → 请求 → 服务
- 横向对比:对比不同模块的性能表现
Q4:指标异常但找不到原因?
A:扩大分析范围:
1. 检查维度因素
- 是否有运营活动(流量突增)
- 是否有系统升级(iOS/Android 版本)
- 是否有网络故障(CDN、服务器)
2. 扩大时间范围
- 查看更长的历史趋势
- 对比去年同期数据
- 排除季节性因素
3. 扩大数据维度
- 查看关联指标(如崩溃率 ↑ 同时操作失败率 ↑)
- 分析用户分布(新增用户 vs 老用户)
- 检查设备分布(低端设备占比变化)
Q5:如何设置告警?
A:建议的告警策略:
核心指标告警
- 崩溃率 > 1%
- 卡顿率 > 5%
- 请求错误率 > 5%
异常告警
- 新增崩溃
- 影响设备数 > 1000 的异常
Q6:数据延迟多久?
A:数据时效性说明:
实时数据(< 3 分钟)
- 应用评分
- 核心指标趋势
- 异常告警
准实时数据(< 5 分钟)
- 关系统计
- 详细列表数据
提示:页面右上角显示数据更新时间。